2022年9月,博士生王乾龙论文Improving Sequence Labeling with Labeled Clue Sentences获人工智能领域重要国际期刊Knowledge-based Systems录用。
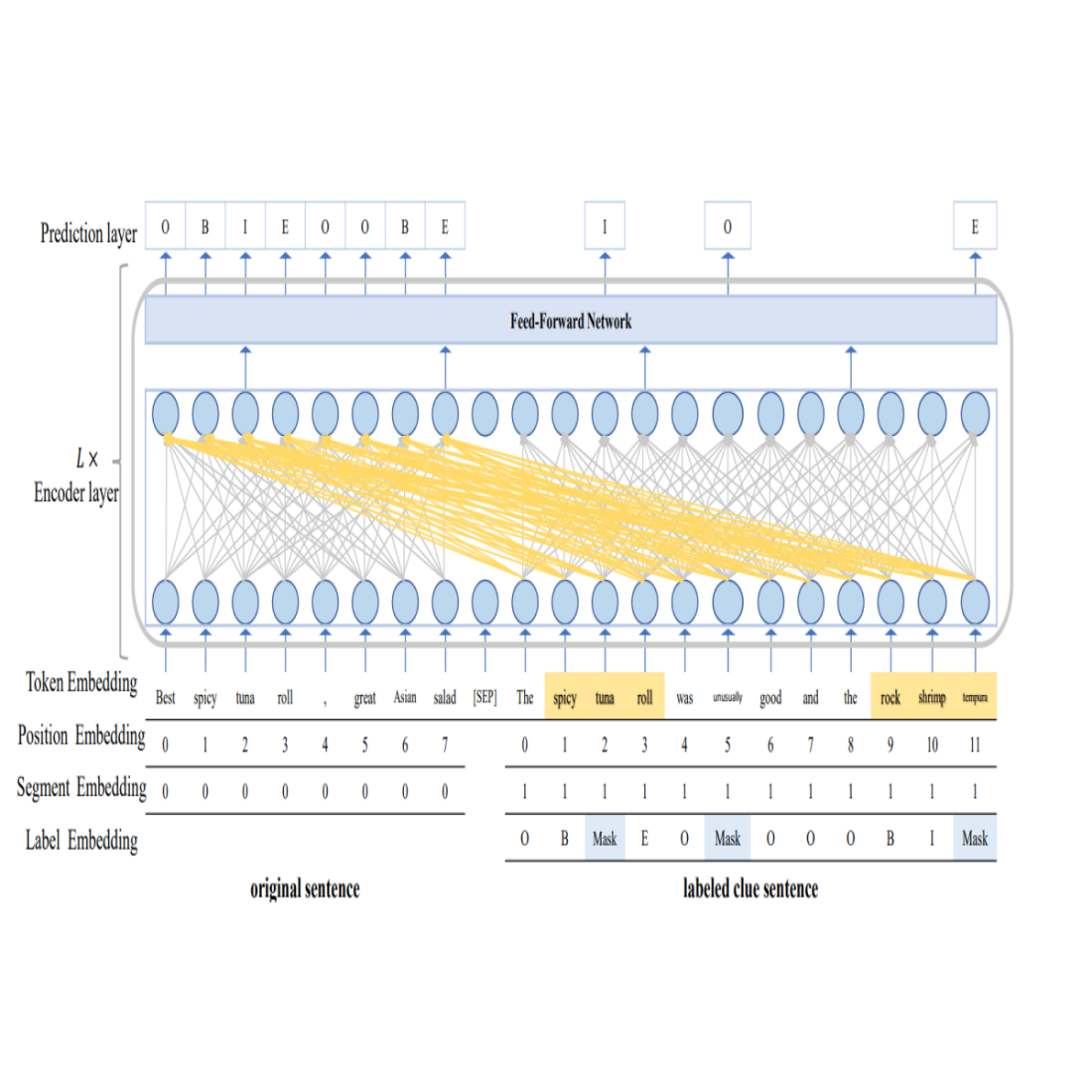
Pre-trained language models (PLMs)预训练语言模型在各种自然语言处理任务(如sequence labeling任务)上取得了显著的成功。目前,现有的序列标注方法通常在一定规模标注数据上微调PLMs,以避免从头开始训练模型。这一微调过程仍然需要一定量的标注训练数据才能有效。然而为序列标注任务获取丰富的标注数据是一个耗时且代价昂贵的过程。本文从一个新颖的角度研究序列标注任务,并提出了一个通用框架。该框架使用标记的线索句子来缓解序列标注数据不足的问题。具体来说,我们首先根据语义(或句法)相关性为训练集中的每个原始句子检索标记的线索句子。在这里,每个原始句子的线索句数量决定了训练集的扩充程度。然后,我们修改了transformer的自注意力机制,使其不仅可以利用原始句子的上下文信息,还可以利用线索句子的上下文和标签信息。此外,我们还设计了一种label mask策略,通过随机mask线索句子中某些token的标签,然后根据与掩码标签对应的token的context预测masked label。这种做法可以避免over-fitting。在三个sequence labeling任务上验证了所提框架的有效性和通用性,包括中英文命名实体识别和情感方面词抽取。大量的实验结果表明,提出的方法可以在这三个任务上获得最先进或具有竞争力的性能。
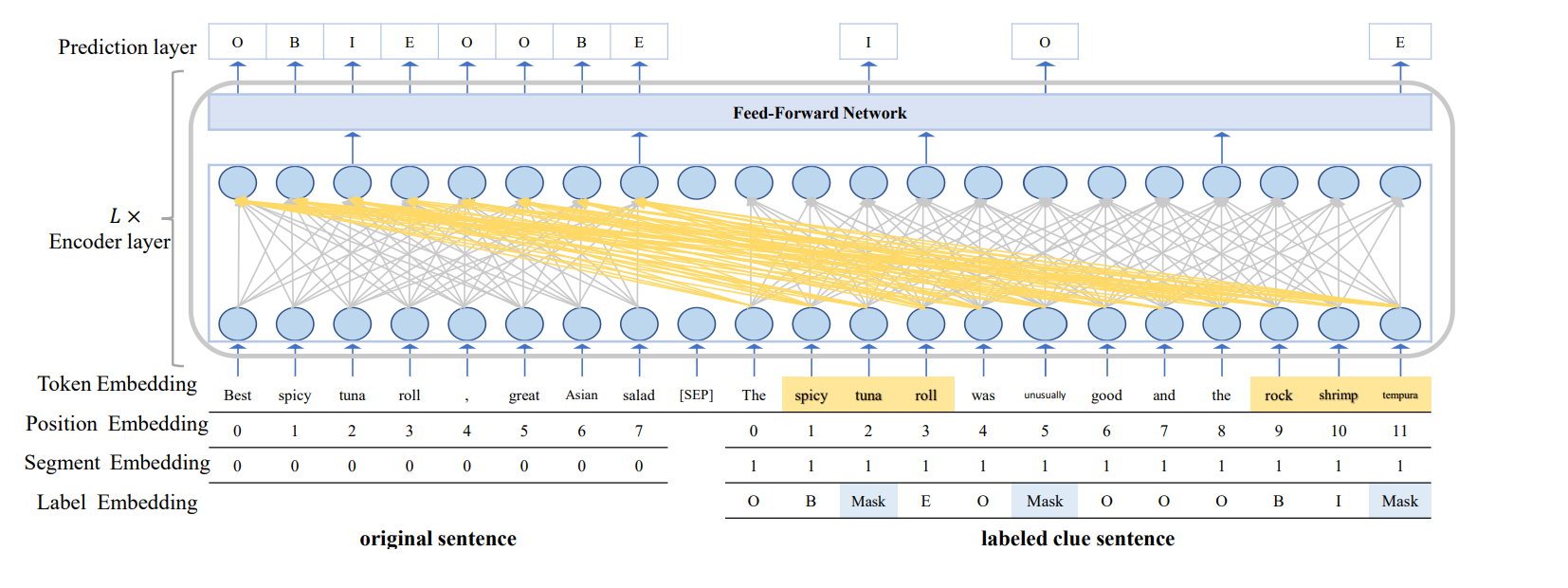
整体架构
Knowledge Based Systems是人工智能领域的重要国际期刊。SCI影响因子8,038。在中科院学术推荐列表(升级版)中为一区期刊,CCF-C类,清华最新版计算机学术期刊推荐列表中认定为B类刊物。
论文信息:
Qianlong Wang, Zhiyuan Wen, Keyang Ding, Qin Zhao, Min Yang, Xiaoqi Yu, Ruifeng Xu*. Improving Sequence Labeling with Labeled Clue Sentences. Knowledge Based Systems. 2022. 109828
doi: 10.1016/j.knosys.2022.109828
https://ieeexplore.ieee.org/document/9860068
审稿:徐睿峰 梁斌
校正:王乾龙 王丹