题目:Exploring Quality and Diversity in Synthetic Data Generation for Argument Mining
会议:EMNLP 2025
作者:鲍建竹、黄钰祺、孙洋、Wenya Wang、张义策、靳伯骏、徐睿峰
单位:哈尔滨工业大学(深圳)、南洋理工大学、鹏城实验室
Argument Mining(论辩挖掘,AM)旨在识别文本中的论辩结构,包括论点(claim)、论据(premise)及其相互支持或攻击的关系。这项任务对于理解自然语言中的逻辑推理与说服机制具有重要意义,在教育评分、法律文书分析和对话系统等领域都有广泛应用。然而,AM的研究长期受限于结构化标注数据的稀缺。由于标注论辩部件及其关系需高度专业化和精细化操作,现有数据集(如AAEC、CDCP、AbstRCT)规模普遍较小,难以支撑高性能的端到端模型训练,制约该领域的发展。
本文借鉴大语言模型(LLM)在合成数据中的进展,提出利用LLM生成AM数据以缓解标注不足问题。然而,由于AM的结构复杂、标注细粒度高,直接用LLM生成高质量的标注数据并非易事。针对这一挑战,本文提出两种互补的合成策略:质量导向合成(Quality-Oriented Synthesis, QOS)与多样性导向合成(Diversity-Oriented Synthesis, DOS)。前者通过结构感知的改写(structure-aware paraphrasing)确保生成样本保留原始标注进而保证标注质量;后者则通过主题头脑风暴与论辩结构模式变换,生成具有更多样的主题与结构的论辩文本。实验结果表明,结合QOS与DOS的合成数据能显著提升模型的AM性能,尤其在低资源场景下效果最为突出,同时展现了方法的可扩展性。
本文的目标任务为端到端论辩挖掘(End-to-End Argument Mining, AM),其定义为同时识别论辩部件(Argument Components, ACI)与论辩关系(Argumentative Relations, ARI)的结构化预测问题。给定输入文本X,任务目标包括两个部分:
1、Argument Component Identification (ACI)
识别论辩部件集合:
其中每个部件 表示为三元组
表示为三元组 ,其中
,其中 和
和 分别为该部件在文本中的起止token 索引,
分别为该部件在文本中的起止token 索引, 表示其类型(如Claim、Premise等)。
表示其类型(如Claim、Premise等)。
2、Argumentative Relation Identification (ARI)
识别部件间的论辩关系集合:
每个关系 表示为三元组
表示为三元组 ,其中
,其中 和
和 分别为源与目标部件,
分别为源与目标部件, 表示关系类型(如Support、Attack)。
表示关系类型(如Support、Attack)。
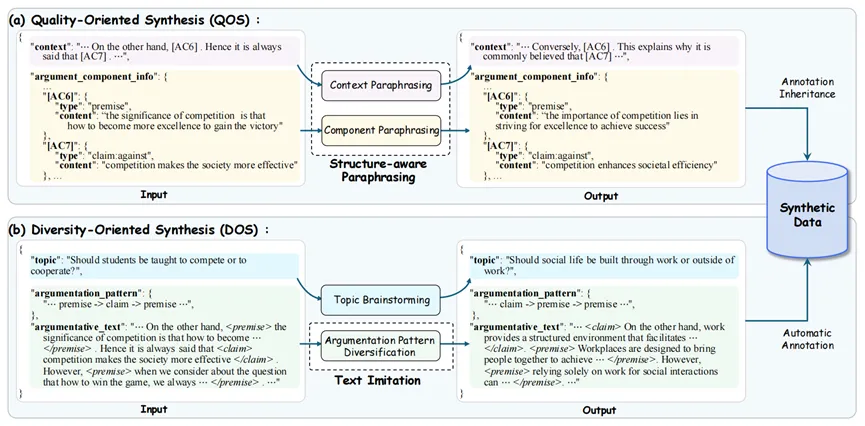
图1数据合成方法框架图
为有效生成论辩挖掘的高质量合成数据,本文提出了两个互补的生成思路(如图1所示):
1. 质量导向合成(Quality-Oriented Synthesis, QOS)
QOS旨在保证标签质量,通过结构感知的改写(structure-aware paraphrasing)实现。该方法以原始样本为基础,利用LLM对文本进行改写,使句法和词汇呈现多样化,同时严格保持原有论辩结构与标签的一致性。实现方案如下:
通过上述改写,QOS能在不引入标注噪声的前提下产生高质量的合成样本,但其主题与论辩结构的多样性有限,为此我们在下文进一步引入了多样性导向合成(Diversity-Oriented Synthesis, DOS)。
2. 多样性导向合成(Diversity-Oriented Synthesis, DOS)
DOS关注拓展主题与论辩结构的多样性。该方法包含三个阶段:
(1)主题生成(Topic Brainstorming):
通过 LLM在原始数据主题的语义范围内头脑风暴,生成大量新的主题,保持domain相关的同时提升主题覆盖度。
(2)结构多样化模仿生成(Text Imitation with Argumentation Pattern Diversification):
LLM在给定新主题及参考样本的条件下,模仿其论辩模式(argumentation pattern,如“claim → premise → premise”),但被要求修改该模式,例如调整部件顺序或增加部件,从而生成结构多样的新论辩文本。
(3)自动标注(Automatic Annotation):
使用在原始人工标注数据上训练的AM模型对生成文本进行自动标注,得到完整的论辩部件与论辩关系信息。
尽管自动标注可能引入噪声,但DOS能有效提高数据的主题覆盖度与结构多样性,从而丰富模型的学习信号。
本文将QOS与DOS生成的数据集分别记为 与
与 。最终的训练采用两阶段策略:
。最终的训练采用两阶段策略:
(1)先使用与(单独或混合)进行初始训练,以利用其规模优势;
(2)再在原始高质量人工标注数据上进行微调,确保模型与目标分布对齐并修正可能的噪声。
实验结果表明,这一策略在多个数据集上均显著提升了模型性能,尤其在低资源场景中效果更为突出。
1、主实验结果
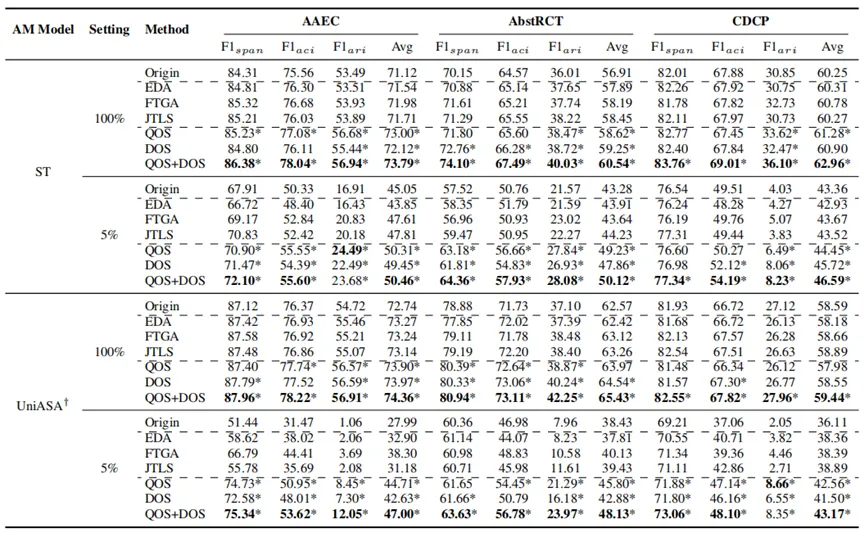
表1在全量(100%)和低资源(5%)训练数据设置下,在 AAEC、AbstRCT 和 CDCP 数据集上的实验结果。
主实验结果如表1所示。从整体上看,无论采用ST还是UniASA模型,本文提出的QOS与DOS均能显著提升模型性能,尤其在仅使用5%数据的低资源情境下,性能提升最为明显。相比之下,单独使用QOS或DOS均能带来稳定增益,而二者结合后表现最佳,说明高质量改写与结构多样性的互补效应在模型学习中发挥了关键作用。此外,与EDA、FTGA和JTLS等通用数据增强方法相比,本文方法在各个数据集上均取得更优的结果,尤其在论辩关系识别任务上提升尤为突出。这表明在保持标签一致性的同时,适度扩展主题与结构多样性能显著增强模型的泛化能力与鲁棒性。
2、消融实验
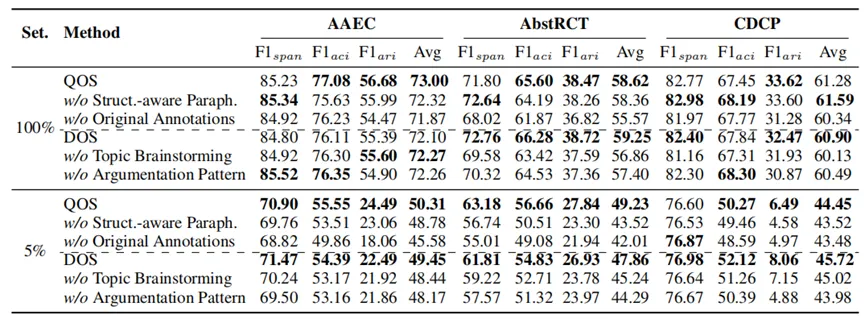
表2消融实验结果
为了进一步分析各模块对整体性能的贡献,本文进行了系统的消融实验,结果如表2所示。在QOS模块中,若去除结构感知改写或不继承原始人工标注,则模型性能明显下降,特别是在低资源条件下下降幅度更大。这说明保证改写文本与原结构标签一致是维持数据质量的关键因素。在DOS模块中,若移除主题头脑风暴或论辩模式多样化生成指令,同样会造成性能衰减,表明增加主题与结构的多样性对于提升模型的泛化能力至关重要。总体来看,消融结果验证了本文提出的各模块在合成数据与模型性能提升中的必要性。
3、相关分析
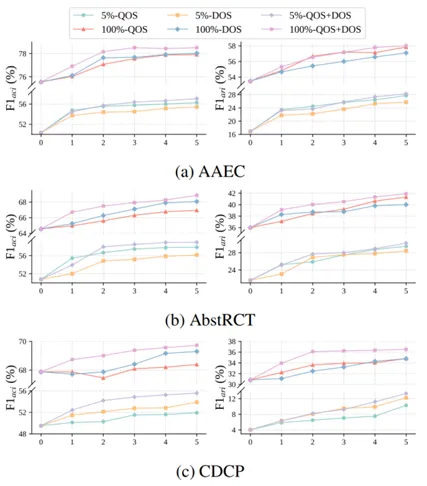
图2合成数据规模对ST模型在三个数据集上的性能影响
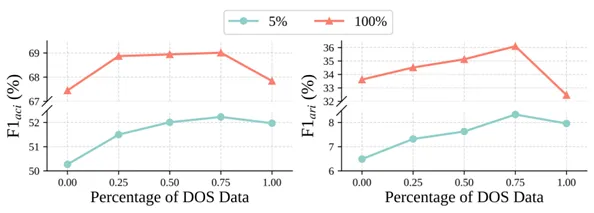
图3 ST 模型中QOS和DOS混合比对CDCP的影响
本文进一步研究了合成数据规模对模型性能的影响,结果如图2所示。实验发现,无论在全量数据还是低资源设定下,随着合成数据量的增加,模型性能均呈现持续上升趋势。这一现象在低资源条件下尤为明显,表明合成数据的扩充能够有效弥补标注数据不足带来的性能瓶颈。此外,在固定总合成规模为原始数据两倍的前提下,本文比较了不同QOS与DOS的比例组合(见图3)。结果显示,纯QOS或纯DOS的方案均非最优,而25%的QOS与75%的DOS的比例实现了性能与稳定性的最佳平衡。该比例在维持高标注准确性的同时最大化了结构与主题的多样性。
本文探讨了利用大型语言模型(LLMs)进行合成数据生成,以缓解论证挖掘(AM)中的数据稀缺问题。我们提出了两种互为补充的方法:面向质量的合成(QOS),通过结构感知的释义来保证标签一致性;以及面向多样性的合成(DOS),通过主题头脑风暴和论证模式多样化来增强主题和结构的新颖性。在三个数据集上的大量实验证明,用QOS 或DOS 生成的样本扩充训练数据,都能显著提升现有AM 模型的性能,尤其是在低资源场景下。此外,将两种方法结合使用还能产生进一步的协同增益效果。