
本期论文速递介绍EMNLP 2025的两篇主会长文。这两篇文章的核心是设计有效的针对性知识蒸馏方法以提升情感分析性能。
论文一:Targeted Distillation for Sentiment Analysis
会 议:EMNLP 2025
作 者:张义策#,谢广宇#,林靖杰,鲍建竹,王乾龙,曾曦,徐睿峰*
单 位:哈尔滨工业大学(深圳)
代码链接:https://github.com/HITSZ-HLT/Sentiment-Distillation
情感分析(sentiment analysis)旨在从文本中识别主观性表达并判断其情感极性,是自然语言处理中的重要研究方向。近期研究表明,大语言模型具备极强的情感理解能力,在多种情感分析任务上均取得了卓越性能。然而,高昂的部署成本严重制约了这些模型在资源受限场景下的可用性。
为降低模型部署成本,许多研究采用知识蒸馏技术来减少模型的体积。现有工作大多聚焦于通用蒸馏(generic distillation),即通过大量精心设计的指令,将大模型的通用能力迁移至小模型中。然而,构建一个足够多样的大规模指令集合极具挑战,这限制了通用蒸馏的实际效果。尤其当教师模型与学生模型的参数规模存在显著的差距时,学生模型往往只模仿教师模型的输出风格,但在具体的下游任务上表现不佳。
针对上述问题,本文研究了面向情感分析的针对性蒸馏方法(targeted distillation for sentiment analysis),即将大型模型的通用情感分析能力迁移至体积较小的模型中。我们首先构建了一个全面的情感分析评估基准,称作SentiBench。该基准涵盖了三大类情感分析相关任务,共包含12个数据集。应用该基准可以全面衡量语言模型在通用情感分析场景下的综合能力。在此基础上,我们还将蒸馏目标拆解为情感相关知识和任务对齐能力,并据此提出了一种两阶段情感分析蒸馏框架。
为系统评估语言模型的情感分析能力,本文构建了情感分析基准SentiBench。该基准涵盖三类典型任务:(1) 基础情感分析(basic sentiment analysis),聚焦于判断文本整体的情感极性;(2) 多视角情感分析(multifaceted sentiment analysis),关注于识别更丰富的情绪维度,包括讽刺、情绪类别、立场倾向、亲密度等;(3) 细粒度情感分析(fine-grained sentiment analysis),深入挖掘文本中的细粒度情感要素,从而获得更加全面的情感描述。典型任务包括方面级情感分析、结构化情感分析等。基于上述任务体系,我们对开源数据集进行了系统性整合,最后构建的评估基准覆盖了12个数据集。
表1: SentiBench任务总览和数据集统计
在蒸馏之前,本文将蒸馏目标拆解为情感相关知识能力(sentiment-related knowledge)与任务对齐能力(task alignment)。情感相关知识能力指模型对文本中情感的理解能力,包括准确解析情感表达、精准定位评价对象,以及掌握必要的背景知识等。该维度决定了模型在情感分析任务中的潜在性能上限。任务对齐能力则指模型遵循具体任务指令和示例的能力,即上下文学习能力。基于这种拆解方式,本文设计了一个两阶段蒸馏框架——Know & ICLDist。
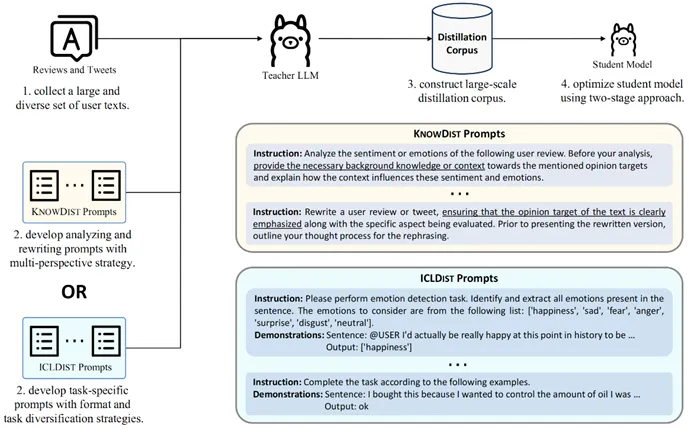
图1:总框架图
第一阶段为知识驱动的蒸馏(knowledge-driven distillation, KnowDist)。该阶段通过分析和重写两种方式,从教师模型中迁移其情感相关知识。为进一步提升情感知识的覆盖广度与深度,本文还引入了多视角提示策略(multi-perspective prompting),以增强蒸馏过程中情感语义的全面性。第二阶段为上下文学习蒸馏(In-Context Learning Distillation, ICLDist),旨在迁移教师模型在情感分析任务中对指令和示例的遵循能力,即其上下文学习能力。为提升学生模型在未见任务上的泛化性能,本文采用了格式多样化和任务多样化策略,增强了蒸馏数据的多样性。
实验设置 本文选用Llama-3-70B-Instruct作为教师模型,并选取Llama-3-1.2B、Qwen-2.5-1.5B、Llama-3-3.2B作为学生模型。为构建高质量的蒸馏语料,我们从IMDb、Yelp、Amazon和Twitter四个来源收集了大量的用户文本,最终构建了一个包含150万条样本的情感分析蒸馏语料库。
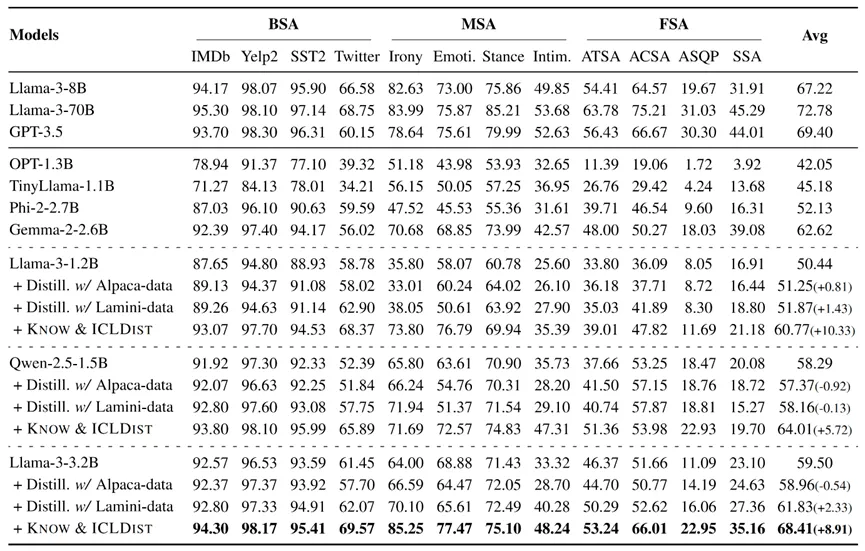
表2: 主实验结果
主实验结果 如上表显示,本文提出的两阶段蒸馏框架Know & ICLDist显著优于通用蒸馏方法,大幅提升了学生模型在情感分析任务上的整体性能。具体而言,通用蒸馏方法(即Distill. w/ Alpaca-data和Distill. w/ Lamini-data)仅带来了有限且不稳定的性能增益,平均 F1 提升不足2.33%,表明迁移通用能力难以有效提升模型在情感分析领域的表现。相比之下,Know & ICLDist实现了显著且一致的性能提升:蒸馏后的1.2B 模型性能超越原始3.2B模型,而3.2B模型则超越原始8B模型。此外,该方法在 Llama-3 与 Qwen2.5 等不同模型架构上均取得稳定增益,展现出良好的通用性与鲁棒性。
论文二:Comprehensive and Efficient Distillation for Lightweight Sentiment Analysis Models
会 议:EMNLP 2025
作 者:谢广宇#,张义策#,鲍建竹,王乾龙,孙洋,王冰冰,徐睿峰*
单 位:哈尔滨工业大学(深圳)
代码链接:https://github.com/HITSZ-HLT/COMPEFFDIST
尽管上述蒸馏方法取得了良好效果,但是其性能依赖于人工编写的指令和大规模的用户文本,由此带来两个关键挑战:(1) 人工编写的指令在数量和多样性上有限,难以全面覆盖情感分析所需的知识维度;(2) 使用大规模用户文本进行蒸馏导致高昂的计算开销,影响了方法的实用性。为应对上述问题,本文进一步提出了一个全面且高效的情感分析蒸馏框架,称作CompEffDist。该框架包含两个核心模块:基于属性的自动指令构建模块与基于难度的数据过滤模块。
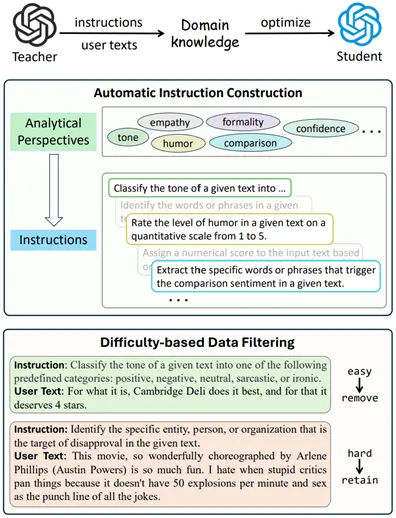
图2:CompEffDist框架图
为了确保蒸馏知识的全面性,指令集合需覆盖广泛的情感分析角度,比如基础维度(如情感极性、情绪类型)、语言表达特征,以及更高层次的语义要素(如修辞手法、背景知识等)。然而,人工归纳这些分析角度并且构建高质量指令极具挑战。受到现有工作的启发,本文提出了一种自动化的指令构建流程:首先从用户文本中识别情感相关的属性,并以此为基础生成多样化指令。如下图所示,该流程包含四个关键步骤:属性枚举(attribute enumeration)、属性聚类(attribute clustering)、任务生成(task generation)和指令生成(instruction generation)。
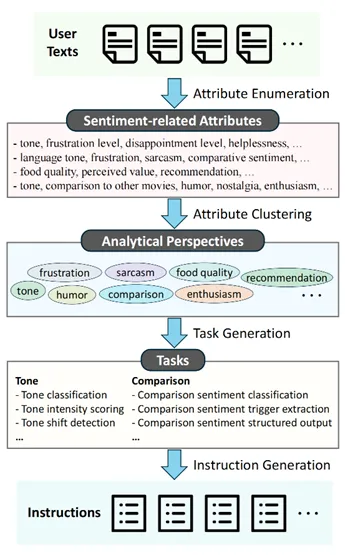
图3:基于属性的自动指令构建示意图
属性枚举与聚类 真实的用户文本天然蕴含了丰富多样的情感属性。例如,对于用户评论
“I wish I could give it zero stars. Whoever thinks this smells like a lemon, needs help. This is the most disgusting, repulsive, overwhelming, stinky cleaner I ever had the displeasure of using.”
该文本同时体现了情感强度(emotional intensity)、挫败感(frustration)、厌恶(disgust)、讽刺(sarcasm)以及产品不满(product dissatisfaction)等情感维度。基于此观察,本文利用教师模型从用户文本中识别情感相关属性。具体来说,我们在2万条用户文本上执行属性提取,共得到了1800个原始情感属性。随后,采用聚类方法对这些属性进行语义归并,最终得到了180个属性簇,每个簇代表一个统一的分析角度。下图展示了一些典型的分析角度。


图4:代表性的分析视角(上)以及生成的典型指令(下)
任务和指令生成 针对每个分析角度,本文引导教师模型进行任务头脑风暴。在此过程中,我们为教师模型提供了若干预定义的任务类型模板,包括分类、回归、信息抽取、结构化输出和开放式生成等,以确保任务形式的多样性与实用性。以分析角度 “tone” 为例,生成的具体任务包括:(i) tone classification, (ii) tone intensity scoring, (iii) tone shift detection, (iv) tone comparison to neutral, (v) tone-related entity extraction, (vi) tone profiling, 和 (vii) tone-based summarization。随后,我们进一步指示教师模型为每个任务自动生成完整、清晰且可执行的指令。上图展示了一个生成指令的典型示例。
为确保蒸馏过程的有效性,用户文本语料需涵盖多样化的上下文类型。例如,在语言表达层面,应包含情感词汇、事实性陈述、比较结构、比喻以及讽刺性表达等多种形式。然而,实现这种多样性通常依赖于大规模语料库,导致蒸馏过程的计算开销显著增加。为缓解这一问题,本文对数据难度进行评估,并采取难度优先的采样策略,以减少简单样本在蒸馏数据中的比例。
基于排序的难度评估指标 本文未采用传统的困惑度(perplexity)作为数据难度的评估指标。原因在于,困惑度衡量模型在整个词表上的概率分布平滑程度,而情感分析任务通常涉及类别化输出(如正面、负面、中性),其目标空间远小于完整词表。在此设定下,全词表概率难以准确反映模型对正确情感标签的判别置信度,因而不适合作为难度评估的依据。为此,我们提出了一种基于排序的难度评估指标。具体而言,对于每个输入样本中的目标预测位置,首先采用 top-p采样策略从模型输出的标签分布中构建一个局部标签候选集;随后,记录真实标签在该候选集中的排序位置;最后,结合该排序位置与候选集的大小,计算出归一化的难度得分。该得分越低,表示模型越容易将正确标签排在靠前位置,样本越简单;反之则视为困难样本。
难度优先采样的策略 旨在保留更具挑战性的样本,同时降低简单样本在蒸馏数据中的比例。具体而言,对同一指令下的多个样本,首先基于上述排序指标评估其难度,然后按难度赋予采样概率——难度越高,被保留的概率越大。最终,通过该策略从原始语料中筛选并保留约50%的样本。这一设计在显著减少计算开销的同时,有助于提升蒸馏数据的信息密度。
实验设置 我们在三个不同的模型家族上进行了实验,具体的教师-学生设置分别为(Llama-3.1-70B-instruct, Llama-3.2-3B-instruct), (Qwen-3-32B, Qwen-3-4B), 以及(Gemma-3-27B-it, Gemma-3-4B-it)。为构建高质量的蒸馏语料库,我们从IMDb、Yelp、Amazon和Twitter四个来源收集10万条用户文本。随后,我们将这些用户文本与指令构建模块生成的指令集进行配对,得到包含10万条样本的初始蒸馏语料库。经过数据过滤模块的筛选,最终得到了一个包含5万条样本的高质量的情感分析蒸馏语料库。
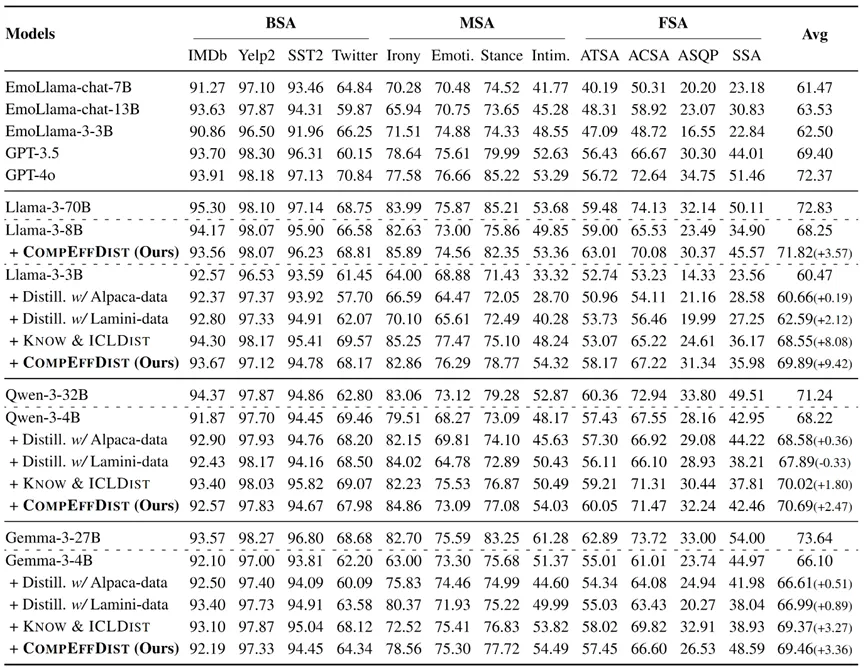
表3: 主实验结果
主实验结果 如上表所示,本文提出的全面且高效的情感分析蒸馏框架CompEffDist可以大幅提升学生模型在情感分析任务上的整体性能,在大多数任务上已能接近教师模型的性能,并显著优于通用蒸馏方法以及人工构造指令的蒸馏方法。具体而言,CompEffDist可以有效实现情感分析能力的迁移,在Llama-3-3B模型上带来了平均9.42%的F1提升,而通用蒸馏方法(即Distill. w/ Alpaca-data和Distill. w/ Lamini-data)提升则有限且不稳定。其次,CompEffDist性能同样优于基于人工构造指令集的蒸馏方法(即上文的两阶段蒸馏框架Know & ICLDist),并展现出极高的蒸馏效率,仅使用5万条样本即可超越Know & ICLDist使用30万条蒸馏样本的性能。此外,我们的方法在三个模型家族上均取得了稳定增益,展现出良好的通用性与鲁棒性。
指令多样性的影响 本文的一个核心观点是,指令多样性是影响蒸馏有效性的一个关键因素。为探究指令多样性对知识蒸馏的影响,我们开展了以下实验。首先,我们考察了在相同数量的蒸馏样本下,指令数量(即多样性)对学生模型性能的影响。如下图所示,随着指令数量的增加,学生模型的性能呈现出持续提升的趋势,表明更多样的指令能够有效提升学生模型的性能。其次,我们对比了本文所用的多样性指令集与之前方法所用指令集的蒸馏效果。如下表显示,使用本文的指令集,仅需2万条样本即可达到Know & ICLDist 在30万条样本下的蒸馏性能。这种蒸馏数据量的极大减少充分说明指令多样性可以提高蒸馏过程的整体效率。
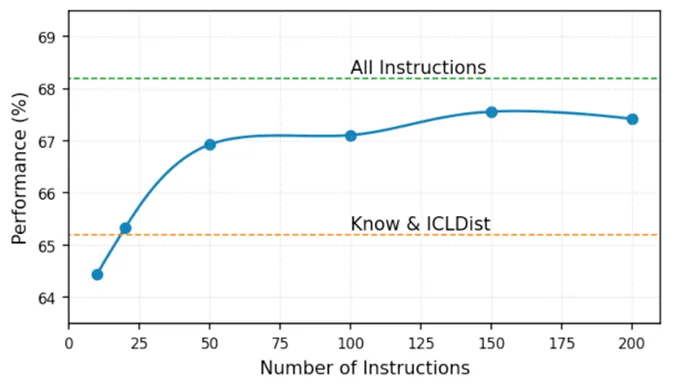
图5: 不同指令数量下学生模型的性能趋势
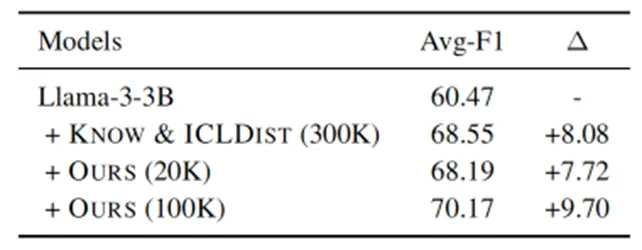
表4: 本文的指令集与之前指令集的性能对比
蒸馏数据量对性能的影响 我们分析了不同蒸馏数据规模对学生模型性能的影响。结果如下图所示,随着数据量的增加,模型性能呈现稳定上升趋势,说明充足的蒸馏样本对于性能提升至关重要。此外,在相同条件下,引入数据过滤模块后,模型在数据利用率方面取得了显著提升:仅使用5万条过滤后的数据,即可达到使用9万条原始数据所实现的性能水平。
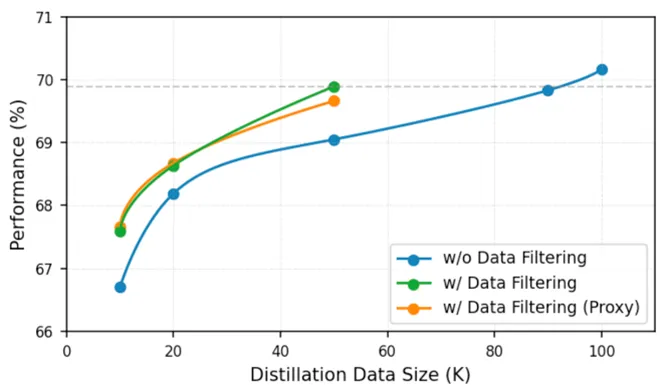
图6: 学生模型性能随蒸馏数据量的变化趋势
数据过滤模块的消融实验 为验证本文提出的基于排序的难度评估指标以及难度优先采样策略的有效性,我们进行了消融实验。结果如下表所示。首先,在难度评估指标方面,传统难度评估指标如困惑度(perplexity)、指令跟随难度(ifd)以及用户文本长度(user text length),性能上均显著低于本文提出的基于排序的难度评估指标,显示了其在类别化输出任务上的有效性。其次,在数据采样策略方面,无论全局采样(global sampling),还是仅采样高难度样本(hard-only sampling),其性能均低于本文提出的难度优先采样策略。
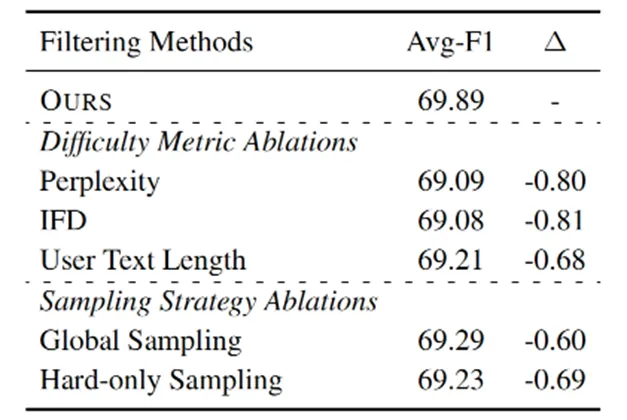
表5: 数据筛选模块消融实验
本研究探索了面向情感分析的针对性蒸馏(targeted distillation for sentiment analysis),旨在从较大模型中迁移通用情感分析能力,以实现高性能的轻量化情感分析模型构建。系统地探索了面向情感分析的针对性蒸馏,为构建高性能、轻量化的情感分析模型提供了新的实践范式。具体如下:
为了便于研究的开展,本研究首先构建了一个全面的情感分析基准SentiBench,涵盖三类典型任务,共12个数据集,能够全面衡量语言模型在通用情感分析场景下的综合能力。
针对通用蒸馏在提升特定领域能力效果有限的问题,本研究则探究针对性蒸馏,以更有效地实现情感分析能力的迁移。本研究通过将蒸馏目标拆解为情感相关知识与任务对齐能力,并提出一种两阶段蒸馏框架Know & ICLDist。第一阶段知识驱动的蒸馏KnowDist聚焦于情感相关知识的迁移,旨在提高模型在情感分析任务中的潜在性能上限;第二阶段上下文学习蒸馏ICLDist聚焦于指令跟随能力的迁移。该框架有效提升了学生模型的情感分析能力,充分验证了针对性蒸馏在提升学生模型情感分析性能的潜力。
然而,上述蒸馏方法仍面临指令多样性不足与计算开销过高的挑战。为此,本研究进一步提出了一个全面且高效的情感分析蒸馏框架CompEffDist,该框架包括两个模块,其中基于属性的自动指令构建模块利用用户文本的蕴含的情感属性自动生成多样化指令集;基于难度的数据过滤模块则通过基于排序的难度指标和难度优先采样策略过滤简单样本,保留较高挑战性的样本。实验结果显示,CompEffDist在不同模型家族中均取得领先表现,仅3B参数的学生模型即可达到20倍规模教师模型的水平,同时在仅使用10%数据量的情况下仍可与两阶段蒸馏方法Know & ICLDist持平,展现出极高的蒸馏效率。