论文题目:Flexibly Utilize Memory for Long-Term Conversation via a Fragment-then-Compose Framework
会议:EMNLP 2025
作者:Cai Ke, Yiming Du, Bin Liang*, Yifan Xiang, Lin Gui, Zhongyang Li, Baojun Wang, Yue Yu, Hui Wang*, Kam-Fai Wong, and Ruifeng Xu*
动机:大型语言模型 (LLMs) 在开放域对话中取得了显著进展,但它们在处理长期对话时仍面临重大挑战,尤其是在缺乏有效的长期记忆方面。目前,一个主流的解决方案是将历史对话不断压缩成摘要作为记忆。然而,这种“压缩式记忆”存在明显缺陷:1)摘要式的记忆在检索时,很容易引入与当前话题不相关或冗余的信息。2)这种方法难以灵活地从不同的历史会话中精确选择和整合关键信息。受认知心理学的启发(如图1所示),人类记忆并非“压缩打包”,而是倾向于将复杂的句子分解为一系列包含基本含义的简单片段或单元来记忆,在需要时大脑再根据当前情景灵活地组合这些记忆碎片。因此,我们提出了一个新颖的长期对话记忆利用框架FraCom,将对话历史“碎片化”为核心信息单元,然后在需要时“组合”这些碎片。
图1 人类基于认知心理学记忆和利用历史对话记忆的例子
方法:我们的 FraCom 框架主要包含三个模块:碎片化 (Fragment)、组合 (Compose) 以及记忆检索与响应生成。
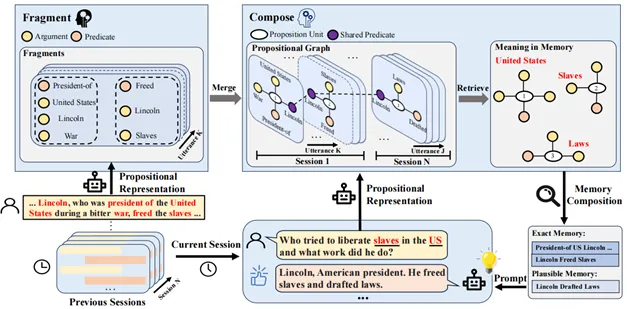
图2 FraCom整体框架
1.碎片化(Fragment)模块:
此模块的目标是从历史对话中提取关键的“记忆碎片”。为了确切寻找什么是核心记忆内容,我们借鉴了认知心理学中的“命题表征”,该理论表示人类在记忆时不需要记住发生的整体情况,只需要明白其中的意义,而来自语言学的命题则是意义的核心,可作为最小的知识单元。为此,我们提示LLMs或训练一个小型的生成模型如BART、T5等将历史对话中的每个句子分解为“谓词”和“论元”,最终历史对话被转换成一系列结构化的命题 。
。
2.组合(Compose)模块:
这个模块负责将零散的“记忆碎片”组织成一个连贯的记忆网络。为了获取命题之间的联系,我们将提取的命题构建为一个动态的命题图 。在图中,每个命题
。在图中,每个命题 构成一个子图
构成一个子图 。该子图的节点
。该子图的节点 包括命题单元
包括命题单元 、谓词
、谓词 和相关的论元
和相关的论元 :
:
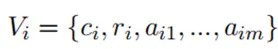
图的边 则连接命题单元与其对应的谓词和论元:
则连接命题单元与其对应的谓词和论元:
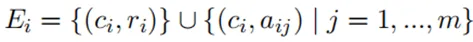
该图最大的特点是会通过连接不同命题,甚至是跨会话的命题中的“共享论元”,将独立的记忆碎片整合成一个有机关联的网络,并且伴随着新会话的加入而增量更新:
详细更新流程如算法1所示:

算法1 命题图动态更新
3.记忆检索与响应生成模块:
当用户输入新的查询时,我们首先也将其转换为命题表征形式,提取出查询中的论元 已被后续检索。随后,由于人类在回忆时往往是相似推断而并非精确回忆,为此我们采用相似性检索,计算查询论元与命题图
已被后续检索。随后,由于人类在回忆时往往是相似推断而并非精确回忆,为此我们采用相似性检索,计算查询论元与命题图 中所有论元节点之间的余弦相似度:
中所有论元节点之间的余弦相似度:
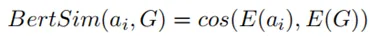
我们设定一个相似度阈值 。如果相似度
。如果相似度 ,则该论元所连接的命题
,则该论元所连接的命题
就被视为相关的记忆并被检索出来。最后,我们将检索到的命题集合 当前对话
当前对话 一起输入到 LLMs 中,以生成最终的、融合了长期记忆的响应
一起输入到 LLMs 中,以生成最终的、融合了长期记忆的响应 :
:
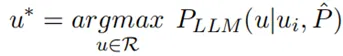
通过这种方式,FraCom能够更精确、更灵活地利用历史记忆,避免了传统摘要方法带来的信息冗余和丢失问题。
在四个长期对话对话数据集(CC, MSC, GC, LME) 上,使用 Qwen2.5-7B, Llama3-8B, ChatGPT 作为基础模型,并与四种主流的摘要式记忆基线方法(Rsum, MemoChat, MemoryBank, COMEDY) 进行了对比。
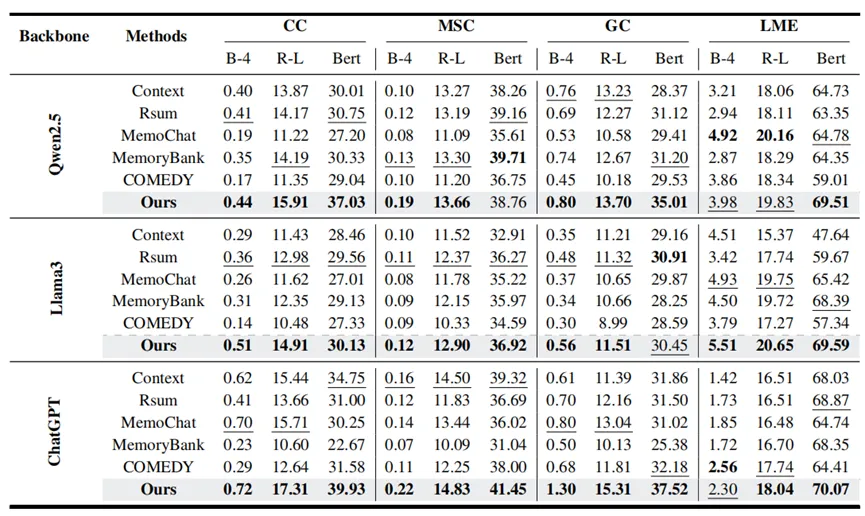
表1 自动指标评估
结果显示,我们的 FraCom 框架在四个数据集上的自动指标 (BLEU-4, ROUGE-L, BertScore) 大部分表现最佳。

表2 GPT-4o评估
我们使用 GPT-4o 评估回复的“参与度”、“拟人性”和“记忆性”。结果显示,FraCom 在大部分数据集上均取得了最高的“记忆性”得分。
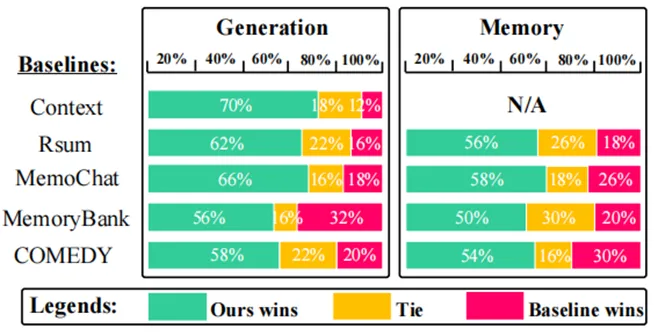
表3 人工评估
人工评估结果显示,与所有基线相比,我们的方法在“生成质量”和“记忆质量”两个方面都获得了显著的胜率。
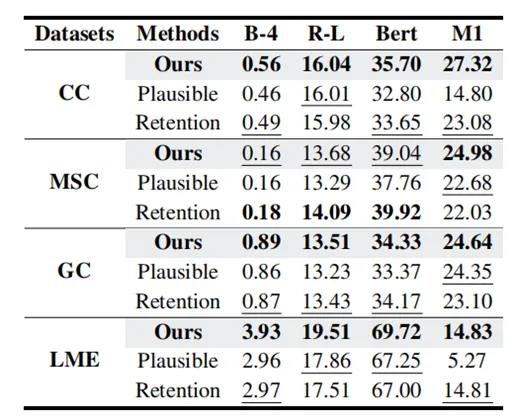
表4 消融实验
移除相似性检索(Plausible Retrieval) 或记忆跨会话保持 (Memory Retention) 模块后,模型的性能(特别是 M1 分数)在 CC 和 LME 数据集上均出现明显下降,证明了这两个模块的必要性。
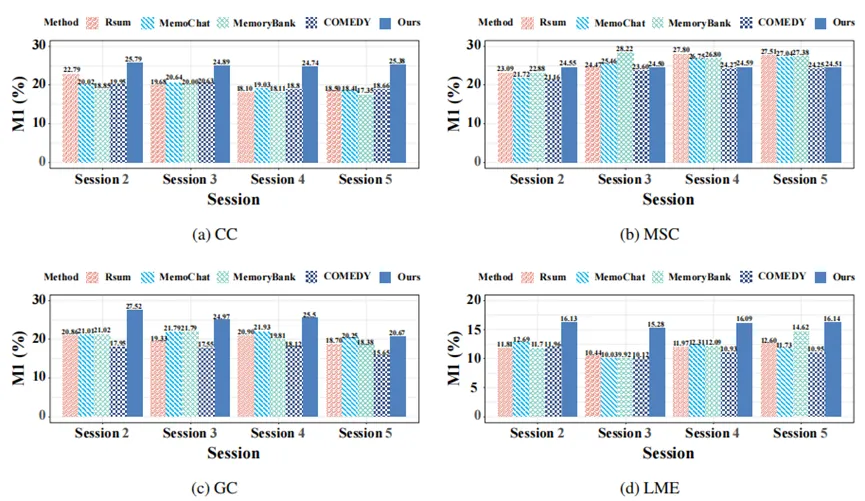
图3 每个会话的具体记忆评估
我们提出了 M1 分数来评估记忆利用效率,利用原文相似度以及与查询相似度的调和平均来计算。实验证明,FraCom 在所有数据集上都取得了接近最优的 M1 分数。图3的柱状图直观地显示,在数据集的几乎所有会话中,我们的方法 (蓝色柱) 的 M1 分数均显著高于其他基线。
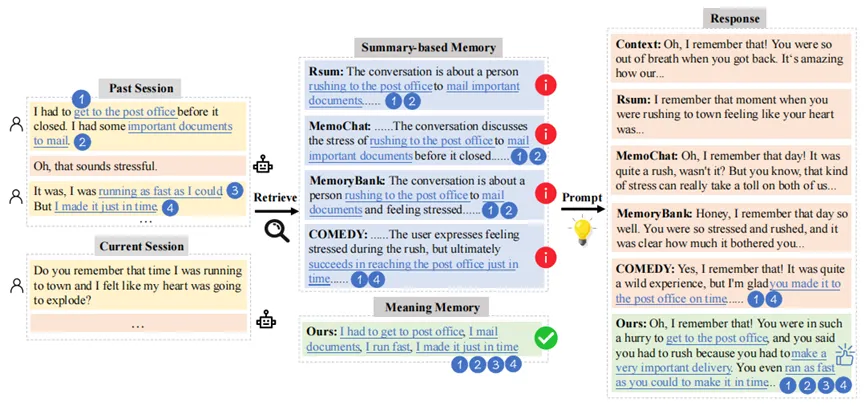
图4 案例分析
摘要式基线方法在回忆时丢失了关键信息(例如只记住了 4 个点中的 2 个)。而我们的 FraCom成功地从历史中检索出了所有 4 个关键记忆碎片,并生成了更准确、更符合上下文的回复。
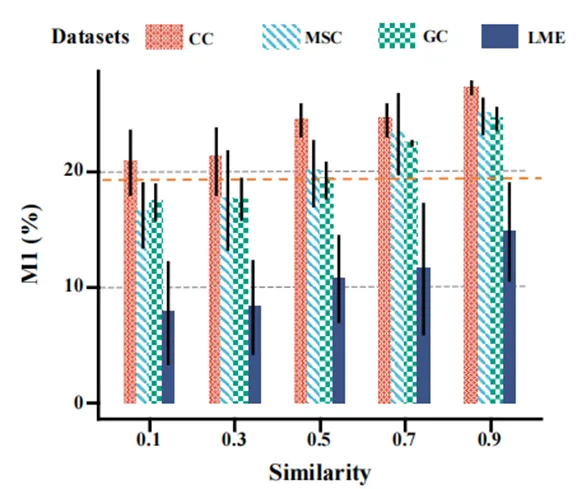
图5 相似度阈值对检索的影响
结果显示,当我们将相似性检索的相似度阈值从0.1 提高到 0.9 时,M1 记忆分数在所有数据集上都显著提高。这表明,更严格的阈值有助于筛选出更准确的记忆。
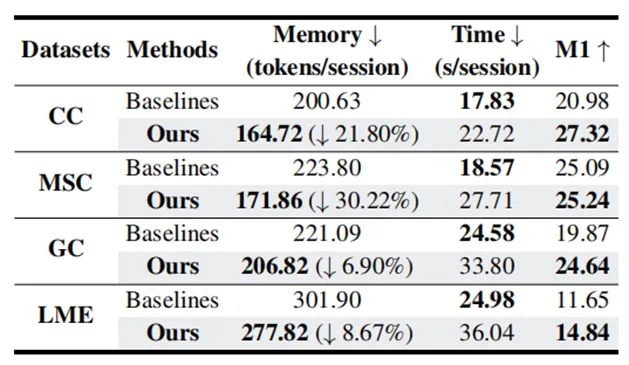
表5 成本分析
FraCom 在显著提高 M1 记忆分数的同时,大幅降低了 7%-30% 的记忆存储开销(tokens/session)。其代价是时间成本增加了 27%-49%。