论文题目:Causal-ERC: A Multimodal Framework with Causal Prompting for Emotion Recognition in Conversations with Large Language Models
会议:AAAI 2026
作者:Ran Jing, Geng Tu, Yice Zhang, and Ruifeng Xu*.
近年来基于LLM的对话情感识别方法取得了大量进展,但现有工作仍然面临两个突出问题:(1)现有基于LLM的情感识别方法往往缺乏对多种模态信息的充分利用,如InstructERC仅利用文本模态信息。基于多模态大模型的情感识别方法,如Emotion-LLaMA和AffectGPT没有考虑对话结构和说话人感知的上下文依赖关系。(2)LLM难以对长程上下文中的依赖关系进行充分建模。分析实验结果表明,LLM在长对话中情感识别性能不佳。这主要来源于忽略了两种潜在的因果关系:话语驱动情感(C1);以及情绪驱动话语(C2)。为了有效整合多模态线索并解决其在处理上下文依赖关系方面的局限性,本文引入心理学中对偶系统理论提出的快思考和慢思考策略,提出了一种基于因果提示和大语言模型的多模态对话情感分析框架Causal-ERC。
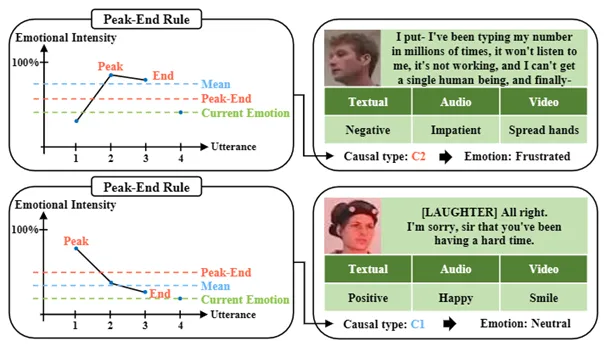
图1 说明因果提示在ERC中作用的例子
为了帮助LLM更有效地建模说话人敏感的上下文和多模态信息,同时可以捕捉对话中的隐式因果关系,从而提升其在对话情感分析的性能,论文提出了Causal-ERC框架,如图2所示。Causal-ERC利用各种模态对上下文信息进行建模,以有效地融合这些模态信息。同时分析每句话的情感强度,从而对因果关系进行分类并且选择相应的因果提示。最后Causal-ERC将融合后的表示与ERC提示得到的序列一起输入到LLM中进行情感识别。
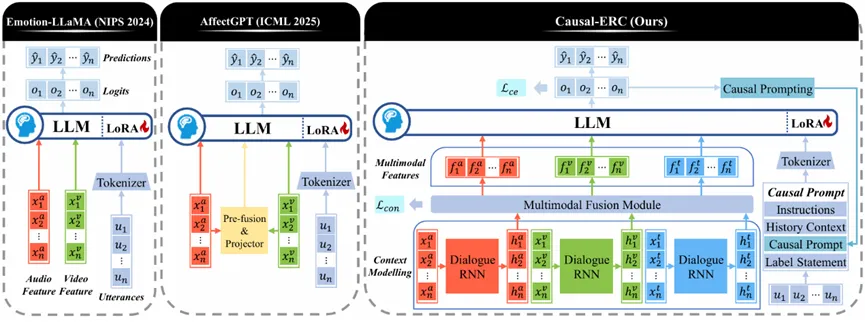
图2 Causal-ERC结构示意图
1.多模态融合
为了帮助LLM捕捉对话中说话人和上下文的交互关系,并且可以有效整合多模态信息用于情感分析,我们首先对每种模态的特征进行建模,将它们融合为统一的表示,然后将结果输入到LLM中。
上下文建模。为了建模说话人感知的上下文信息,我们利用DialogueRNN作为编码器,为每个话语导出隐藏表示:
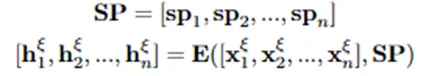
多模态融合。为了有效整合多模态信息并捕捉不同模态之间的一致性,我们设计了一个多模态融合模型,该模型由三个多头注意力层组成,建模文本、音频、视频模态之间的注意力关系:
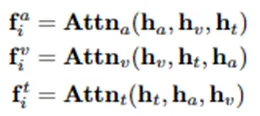
2.因果提示
为了捕捉对话中的隐式因果关系,从而增强LLM对长期语境的建模能力,论文引入了因果提示。首先,为了判断每句话的因果类型,应用峰终定律,根据情感强度对每个话语的因果关系进行分类。然后,为了引导LLM根据句子的因果类型针对性地调整注意力分布,根据识别出的因果类型设计定制的因果提示。整个流程概述于算法1中。

算法1 因果提示的流程
峰终定律。峰终定律是一种心理学启发式方法,它表明人们对一段经历的评价主要基于其最强烈时刻(“峰”)和结束时刻(“终”)的感受,而不是基于整个经历中每个时刻的平均感受。这条定律解释了为什么人们对事件的记忆往往会受到情绪激烈的时刻和最终印象的显著影响。具体来说,这意味着某些话语,尤其是那些情绪强度高或出现在结尾的话语,会对人们对整个对话的情感感知产生更强烈的影响。
在两个多模态对话数据集(IEMOCAP,MELD)上,将Causal-ERC与现有的方法进行了对比:
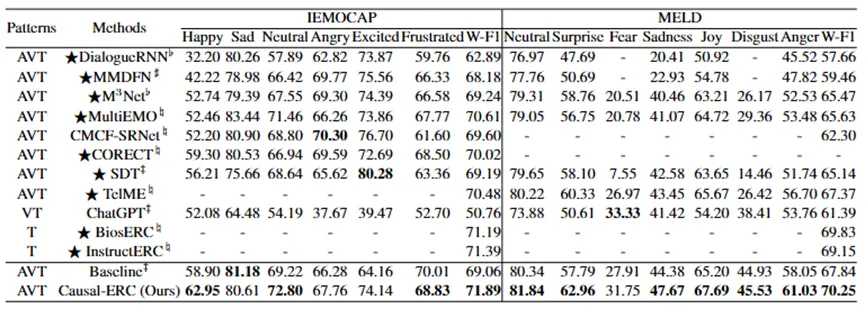
表1 总体实验结果
结果显示,我们的Causal-ERC在两个数据集的性能均超过了现有的方法。

表2 消融实验结果
移除一致性损失,多模态融合或因果提示模块后,模型的性能均有所下降,证明了它们的必要性。
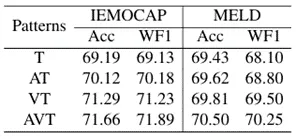
表3 多模态分析实验
随着模态数量的增加,Causal-ERC的性能提高。说明模型可以有效融合多模态信息。
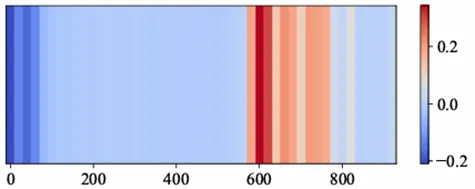
图3 引入因果提示之后,不同位置token的注意力分数的变化情况
引入因果提示之后,模型对更远处token的注意力分数提高,对更近处token的注意力降低。说明该方法可以提升LLM建模长上下文的能力。
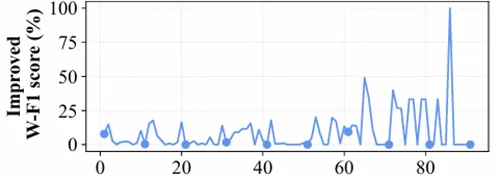
图4 引入因果提示之后对话中各个长度的句子的性能提升情况
引入因果提示之后,模型的性能在各个位置普遍提升,在长对话的提升尤为明显。
本文提出了一种基于多模态
LLM
的新型因果提示框架
Causal-ERC
,用于多模态对话情感分析。
Causal-ERC
融合了多模态信息,并利用说话人信息进行语境建模。此外,
Causal-ERC
能够通过峰终定律分析每个话语的因果关系,并选择相应的因果提示,从而提升长期语境建模能力。在
IEMOCAP
和
MELD
数据集上的大量实验验证了
Causal-ERC
的有效性。