2025年12月,博士生陈诗炜的论文《TGRAG: Retrieving on a Topic Graph for Long Document Question Answering》获期刊Neurocomputing正式录用。该期刊为人工智能与机器学习领域的国际知名期刊,影响因子为6.5,分区为JCR Q1,在CCF推荐列表中为 C类期刊,中科院分区为二区。
长文档问答任务要求模型在成千上万字甚至更长的文档中,准确定位与问题相关的关键证据,并在多段信息之间建立联系、完成整合推理,最终给出可信且一致的回答。然而,传统检索增强生成框架多以局部语义相似度为核心进行段落/句子检索,往往忽视文档内部天然存在的主题结构与跨段依赖关系,容易造成证据片段化、冗余堆叠或关键链路缺失,使得模型在需要跨段推理、跨主题整合或多跳推断的场景中表现受限。为突破这一瓶颈,本文提出基于主题图的检索增强生成框架 TGRAG。该方法受到人类“工作记忆”理论启发,将长文档组织为可被持续激活的主题块,并在此基础上构建稀疏但结构清晰的主题图,使证据组织从“相似度驱动的散点检索”转向“结构驱动的链式聚合”。在检索阶段,TGRAG引入激活扩散机制:首先由问题相关的主题节点触发激活信号,再沿主题图扩散以召回与之结构关联的跨段证据,从而更高效地定位潜在证据链并减少无关冗余;随后结合重排模块筛选高质量证据子图,输入生成模型完成结构感知的答案生成,使输出在可解释性与逻辑连贯性上更具优势。在三个公开长文档问答数据集上的实验表明,该框架在两种LLM评测标准下均取得最优平均排名;进一步的消融实验也验证了主题抽取、主题图建模与扩散激活等关键组件对性能提升的核心贡献。
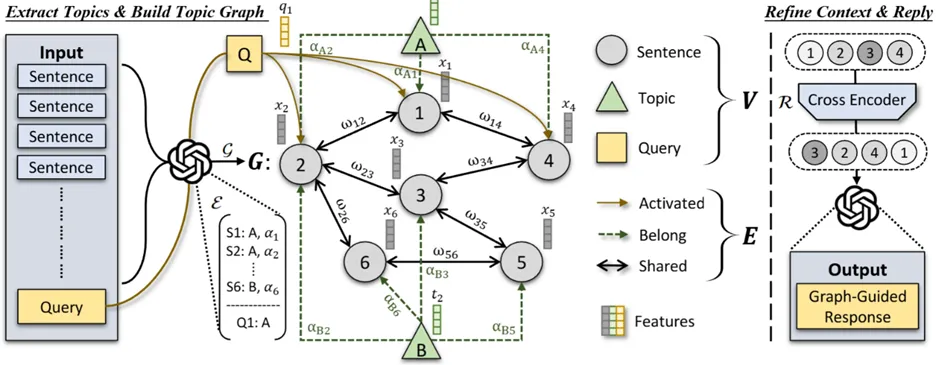
模型总体框架
在NarrativeQA/HotpotQA/MuSiQue三个LDQA数据集上对TGRAG进行评测。下表总结了数据集信息。
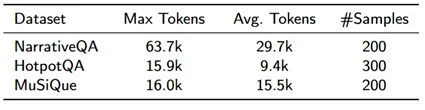
数据集基本信息
采用LLM-as-a-Judge的双标尺评分(LR-1严格、LR-2宽松),分别对比了retrieval-only、长上下文LLM变体、以及结构化检索/GraphRAG类方法。下表显示了TGRAG在三数据集、两种评分下均为最优。
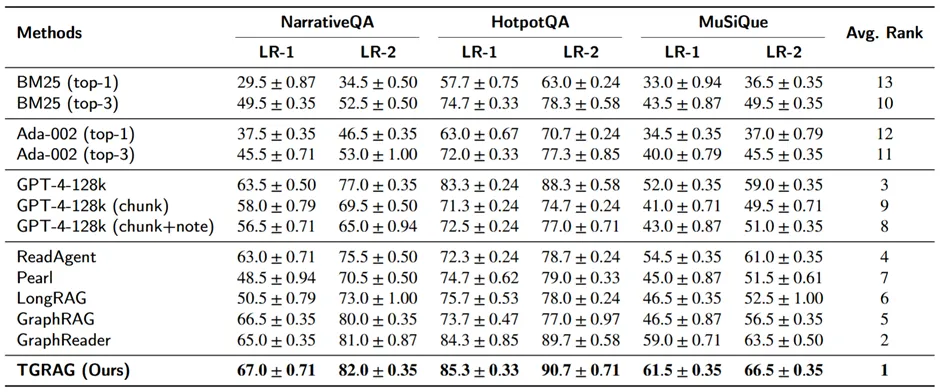 总体性能实验结果
总体性能实验结果
论文信息:
Shiwei Chen, Bin Liang, Yue Yu, Kam-Fai Wong, Hui Wang, Ruifeng Xu*. Retrieving on a Topic Graph for Long Document Question Answering, Neurocomputing,Volume 669,2026,132447