论文信息:
Shiwei Chen, Bin Liang, Yue Yu, Kam-Fai Wong, Hui Wang, Ruifeng Xu*. Retrieving on a Topic Graph for Long Document Question Answering. Neurocomputing. 2026. vol 669, 132447
doi: 10.1016/j.neucom.2025.132447
https://www.sciencedirect.com/science/article/pii/S0925231225031194
长文档问答(LDQA)中,LLM直接“整篇喂入”成本高且容易丢失关键信息(Lost-in-the-Middle)。传统RAG虽然能检索,但常把检索预算浪费在近重复片段上,同时把互相关联的证据打散到超长的提示里,导致影响推理连贯性。认知语言学的“工作记忆”理论启发我们:人类阅读更像是维持少量“主题块(Topic Chunks)”,需要时再激活细节,而不是在密集的句子级图里逐边搜索。基于此我们提出Topic Graph Retrieval Augmented Generation (TGRAG),总体框架如图所示。
TGRAG总体框架
TGRAG的核心是“主题单元 + 稀疏主题图 + 一步扩散激活”的结构化检索,下面的算法总结了其主要步骤。第一步,主题抽取(Topic Extraction):将文档切成句子级单元,并用LLM为每句分配高层主题标签,同时为query抽取query topic(实现中用 GPT-4o 作为主题标注器,并给出对应提示模板)。第二步,建图(Topic Graph Construction):把句子作为节点,依据“共享主题 + 语义相似”建立边并剪枝,得到稀疏、query-anchored的 topic graph(近似“粗粒度主题骨架”)。第三步,图引导检索(Activation–Diffusion Retrieval):将结构扩散信号与语义相似信号线性融合,选 top-K 句子作为候选证据,再用 cross-encoder 精排取 top-L 组成最终上下文,发送给LLM生成答案。

TGRAG算法描述
我们在NarrativeQA/HotpotQA/MuSiQue三个LDQA数据集上对TGRAG进行了评测,下表总结了这些数据集的基本数据。
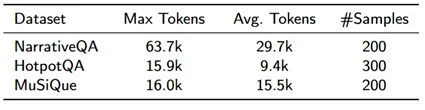
数据集基本信息
采用LLM-as-a-Judge的双标尺评分(LR-1严格、LR-2宽松),分别对比了retrieval-only、长上下文LLM变体、以及结构化检索/GraphRAG类方法。可以发现TGRAG在三个数据集、两种评分下均为最优。
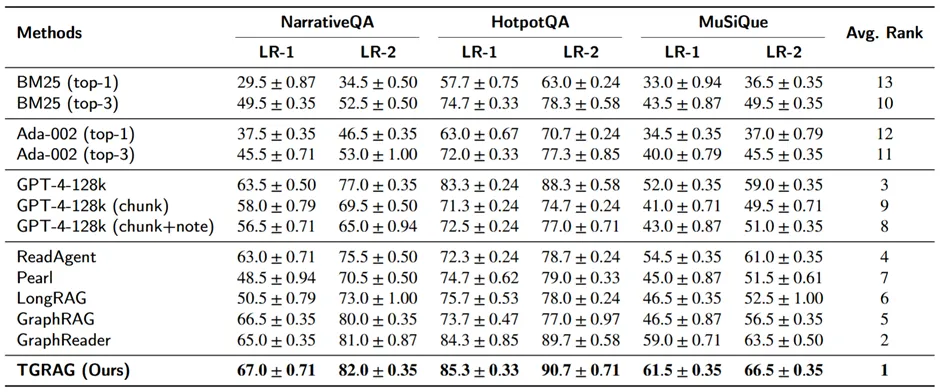
总体性能实验结果
在NarrativeQA上的消融分析也显示,去掉主题抽取、去掉激活扩散、去掉主题图、或用更简单的点乘重排都会下降,说明TGRAG的各模块均有贡献。
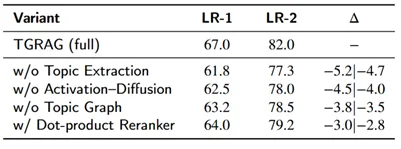
消融实验结果
在对TGRAG的进一步探索分析中,我们发现,在这个框架下:主题节点数k增加带来收益,但在k≈7 后趋于饱和;图稀疏度(边阈值τ)需要在“覆盖”与“噪声/上下文长度”间折中,默认τ=0.15 附近效果最好。
TGRAG用“主题抽取+稀疏主题图+激活扩散检索”的方式,把长文档证据组织成更符合“主题块”的结构,再配合cross-encoder精排,把有限检索预算集中在更连贯、互补的证据上,从而更好地支持了长文档问答生成。