2026年1月,研究团队博士生涂耿和井然合作的论文《Is Multimodal Conversational Emotion Recognition Satisfactory? Exploring the Gaps in Performance, Generalization, and Confidence》获Pattern Recognition期刊录用。
多模态对话情感识别(MERC)领域的最新进展主要集中在说话人感知上下文建模和多模态融合方面。围绕这一研究领域,本文从性能、泛化和置信度三个方面对最新方法进行了深入评估和分析讨论。主要包括三个方面:
(1) 现有MERC模型性能是否足够?
评估分析发现现有模型仍然难以实现有效的多模态融合。尽管基于图卷积网络(GCN)的融合方法通常表现出更优的性能,但过于复杂的架构往往导致结果下降。即使在大语言模型(LLM)中,情感转换问题仍然没有得到充分解决。未来的工作应该考虑开发自适应融合和混合框架,以整合小型模型和基于LLM的模型的优势,同时推进情感转换建模。
表1 预训练模型(PLM)在不同模态下的MELD和IEMOCAP数据集上的性能对比
表2 LLM在MELD和IEMOCAP数据集的性能对比
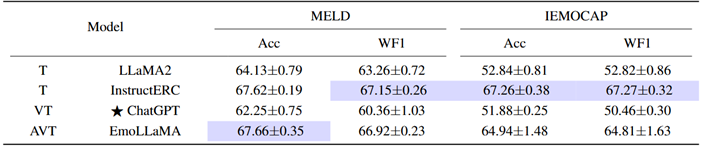
表3 将LLM表示集成到小模型的性能

(2) 现有MERC模型能否泛化到不同的场景?
评估和分析发现现有模型的泛化能力有限。小型模型在处理跨主题和跨说话人转换方面表现更佳,而基于LLM的模型在多个数据集上总体表现均衡。将LLM表示集成到小模型中可以显著提升跨场景性能。未来的研究应探索更有效的跨场景泛化策略,并追求跨越文化、语言及其他语境差异的现实泛化,以确保在真实世界的对话中具有稳健性。
表4 PLM和LLM在跨说话人,数据集,和话题的性能对比
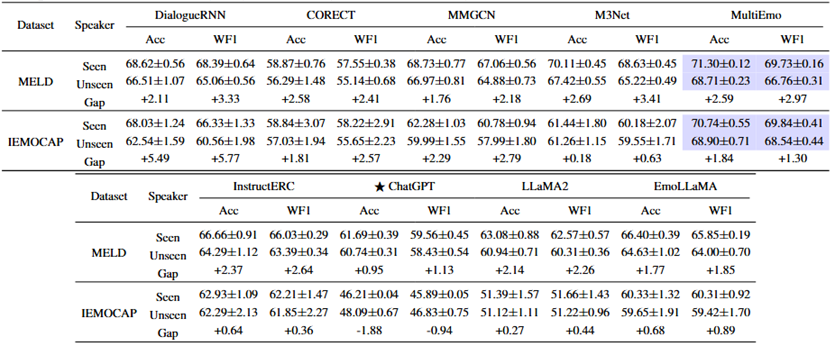
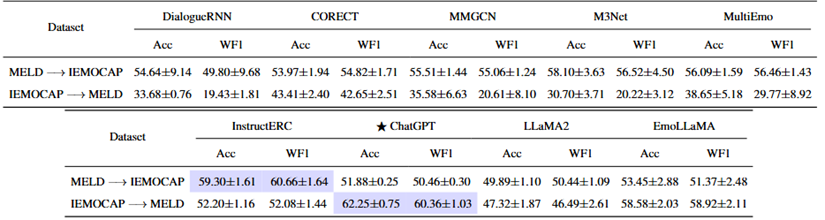
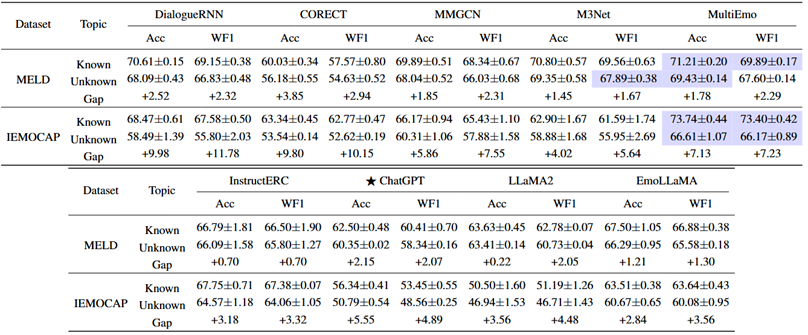
表5 将LLM表示集成到小模型在跨数据集上的性能

(3) 现有MERC模型的置信度是否可信?
评估和分析发现现有MERC模型通常过于自信,而目前的置信度校准方法效果有限,甚至可能对性能产生负面影响。未来的研究应考虑开发MERC专用校准技术,因为校准良好的预测能够更好地反映真实的不确定性并减少偏差,从而提高可信度。
本文通过对现有MERC模型进行严格的评估,包括在未知场景上的测试,分析发现了不同模型之间的关键优势、劣势和协同效应,并凸显出置信度校准在提高模型可靠性和公平性方面的关键作用。本文所进行的全面评估和深入分析结果以及所发现的见解,为推进MERC朝着更稳健、更具泛化性和更值得信赖的情感理解方向发展提供了线索。
表5 MELD和IEMOCAP数据集上PLM和LLM的置信度对比
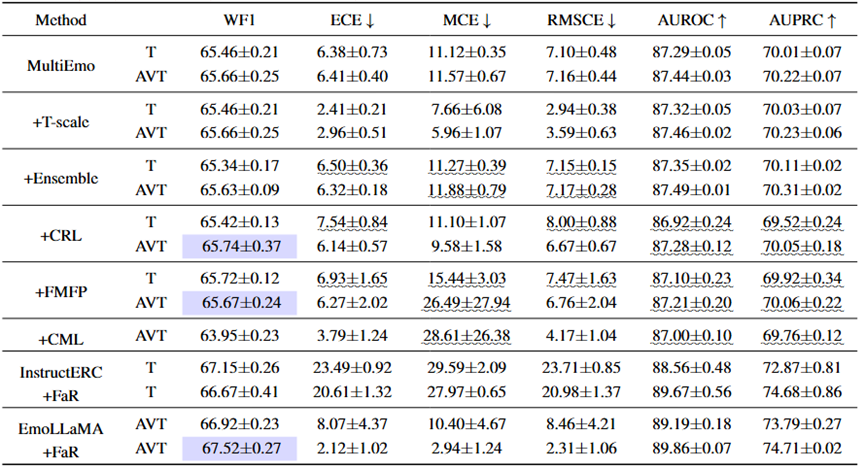
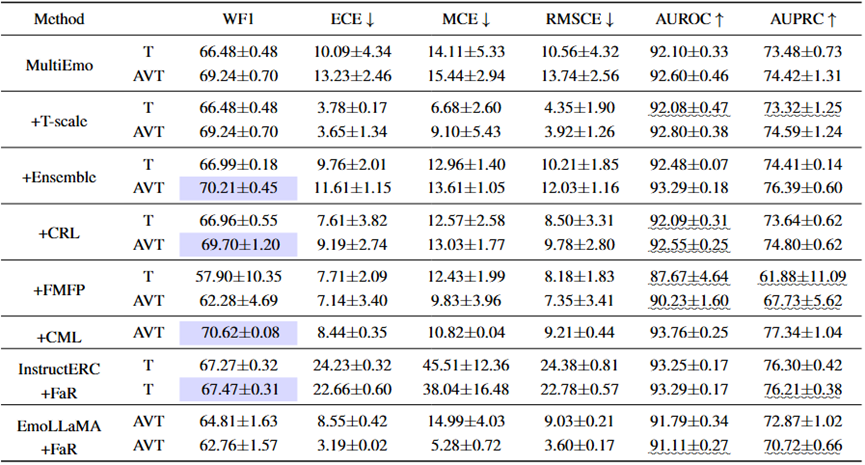
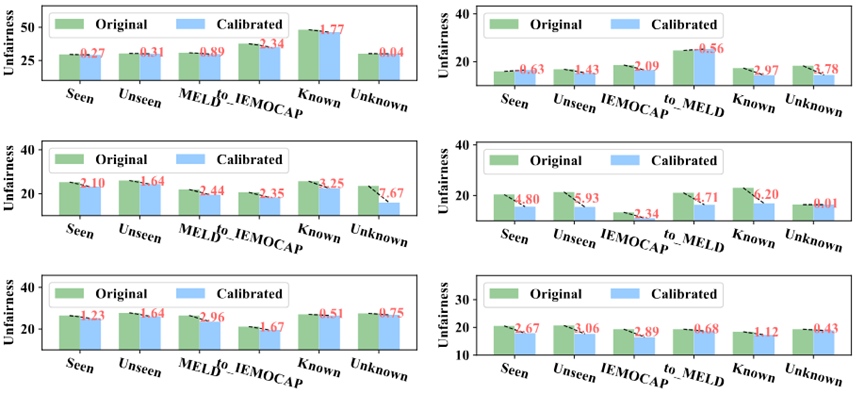
图1 使用置信度校正前后,ERC模型的可靠性变化。从上至下:小模型,单模态大模型,多模态大模型
Pattern Recognition是模式识别与人工智能领域的重要国际性期刊,影响因子7.6,JCR Q1期刊,在中科院学术推荐列表中为一区期刊。
论文信息:Geng Tu#, Ran Jing#, Xuan Luo, Erik Cambria, Wenjie Li, and Ruifeng Xu∗. Is Multimodal Conversational Emotion Recognition Satisfactory? Exploring the Gaps in Performance, Generalization, and Confidence. Pattern Recognition. 2026.