2025年8月EMNLP 2025会议(The 2025 Conference on Empirical Methods in Natural Language Processing) 论文录用结果公布。研究团队共有六篇长文获录用,其中五篇获主会录用,一篇获Findings of EMNLP录用。EMNLP由国际计算语言学会(ACL)主办,是自然语言处理领域的国际顶级学术会议,在中国计算机学会推荐会议列表为B类会议。本次会议将于2025年11月5日-9日在苏州召开。录用论文信息如下:
题目:Flexibly Utilize Memory for Long-Term Conversation via a Fragment-then-Compose Framework
作者:Cai Ke, Yiming Du, Bin Liang, Yifan Xiang, Lin Gui, Zhongyang Li, Baojun Wang, Yue Yu, Hui Wang, Kam-Fai Wong, Ruifeng Xu*
类型:Main Conference
简介:大型语言模型(LLMs)在从对话历史中提取有用信息以增强长期对话中的响应方面取得了显著突破。然而,尽管通过摘要历史对话来保留有用信息取得了不错的性能,但这种方法可能会引入不相关或冗余的信息,导致在记忆检索过程中难以灵活地从不同会话中选择以及整合关键信息。为解决这一问题,我们提出了一种名为FraCom的先碎片后组合框架,这是一种专为长期开放域对话设计的新型记忆利用方法。具体而言,受认知心理学中命题表征概念的启发,FraCom首先将对话历史表征为一系列谓词与论元的命题形式,以碎片化的方式保留对记忆有用的关键信息。然后,该框架基于共享论元之间的连接,为对话历史构建命题图。在检索时,会对当前用户查询进行命题表征,并根据其论元从命题图中灵活地检索相关所需记忆命题。这在根本上实现了对长期记忆中相关信息的灵活高效利用,从而能够针对用户的当前查询生成更具有记忆能力的响应。在四个长期开放域对话数据集上的实验结果表明,本文的FraCom框架能有效提升记忆利用率,并增强LLMs的响应生成能力。
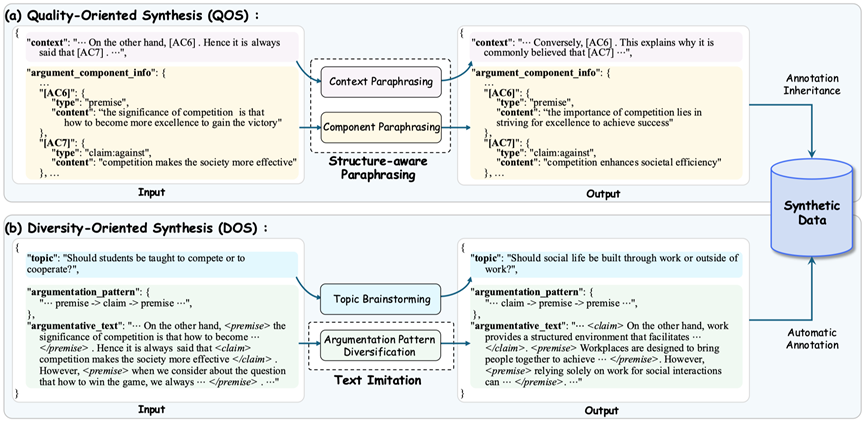
题目:Exploring Quality and Diversity in Synthetic Data Generation for Argument Mining
作者:Jianzhu Bao#, Yuqi Huang#, Yang Sun, Wenya Wang, Yice Zhang, Bojun Jin, Ruifeng Xu*
类型:Main Conference
简介:论辩挖掘(Argument Mining)领域的发展,长期以来面临一个核心难题:带有论辩结构标注的训练数据十分稀少,而人工标注的成本又非常高。近年来,利用合成数据来缓解数据稀缺问题,在自然语言处理领域已展现出巨大潜力。借鉴这一思路,本研究旨在探索如何运用LLMs,为论辩挖掘任务自动合成高质量的训练数据。为此,我们从两个相辅相成的角度着手:第一是“注重质量”,通过一种能保留原始训练数据论辩结构的改写技术,在合成新数据的同时确保标注的准确性;第二是“注重多样性”,目的是生成主题和论辩结构都更加丰富新颖的合成数据。实验结果证明,将我们生成的合成数据(特别是混合使用上述两种方法所产生的数据)加入训练后,无论是在数据充足还是资源有限的情境下,都能显著提升现有论辩挖掘模型的表现。不仅如此,实验还发现生成的数据越多,模型性能就越好,这也充分证明了我们所提出的方法具有良好的可扩展性。
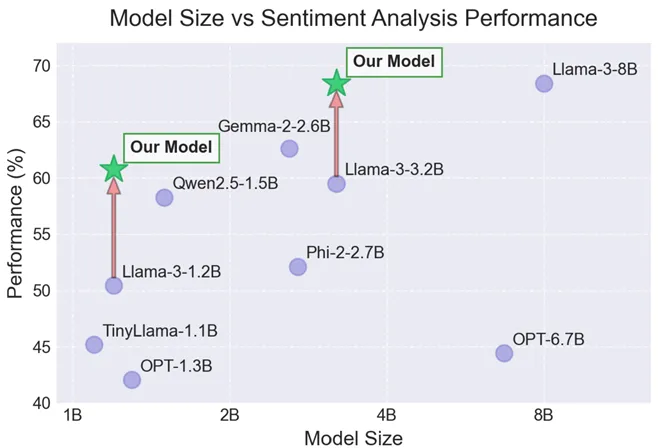
题目:Targeted Distillation for Sentiment Analysis
作者:Yice Zhang#, Guangyu Xie#, Jingjie Lin, Jianzhu Bao, Qianlong Wang, Xi Zeng, Ruifeng Xu*
类型:Main Conference
简介:本文研究了如何通过知识蒸馏方法构建体积小且实用的情感分析模型。本文将待蒸馏的目标分解为Knowledge和Alignment,并据此提出了一种两阶段蒸馏框架。此外,为了全面且系统地评估模型的情感分析能力,本文构建一个包含12个数据集的情感分析评估基准,称为SentiBench。在该基准上的大量实验表明,提出方法可以显著地增强小模型在多个情感分析任务上的性能。同时,得到的模型在未见任务上展现出良好的泛化能力,相较现有小模型具有较强的竞争力。
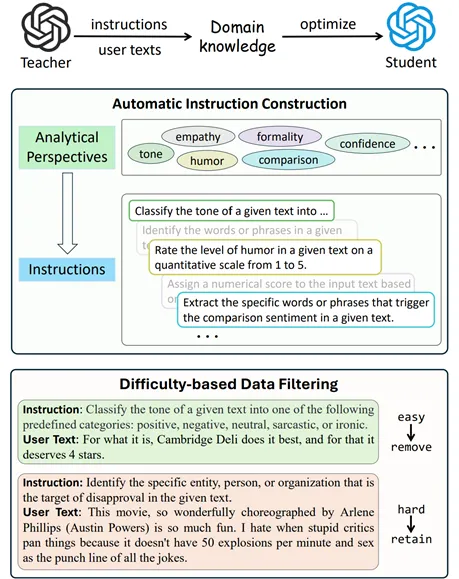
题目:Comprehensive and Efficient Distillation for Lightweight Sentiment Analysis Models
作者:Guangyu Xie#, Yice Zhang#, Jianzhu Bao, Qianlong Wang, Yang Sun, Bingbing Wang, Ruifeng Xu*
类型:Main Conference
简介:最近的工作利用知识蒸馏方法构建体积小且实用的情感分析模型。这些方法依赖于人工编写的指令和大规模用户文本。这些方法尽管取得了不错的结果,但面临着两个关键挑战:(1) 人工编写的指令在多样性和数量上有限,难以保证蒸馏知识的全面性;(2) 使用大规模用户文本带来了高昂的计算代价。为此,本文提出了CompEffDist,一个全面且高效的情感分析蒸馏框架。该方法包含两个核心模块:基于属性的自动指令构建模块和基于难度的数据过滤模块。这两个模块分别解决上述两个挑战。本文在多个模型系列(Llama-3、Qwen-3和Gemma-3)上进行了实验。结果表明,提出方法可以使得3B的学生模型在大多数任务上性能可以匹敌参数量大20倍的教师模型。此外,提出方法在数据效率上显著优于基线方法,仅使用10%的数据即可达到相同的性能水平。
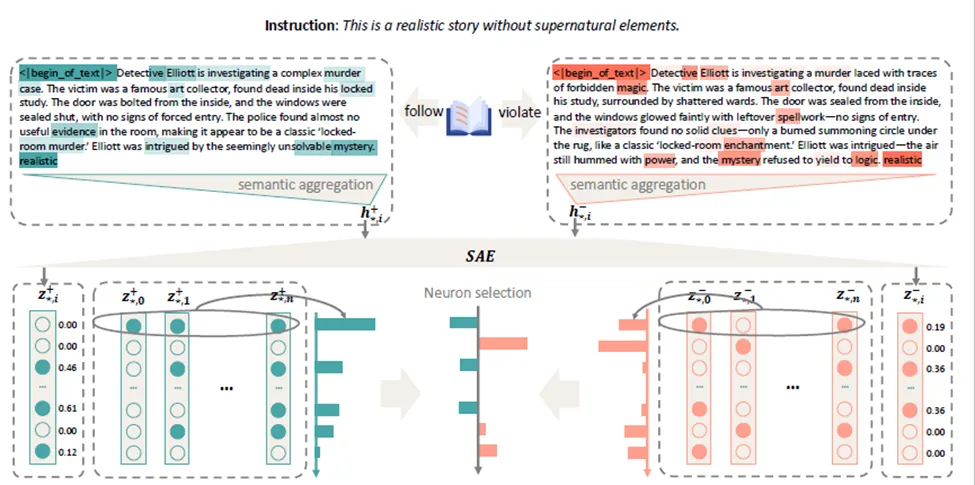
题目:Sparse Activation Editing for Reliable Instruction Following in Narratives
作者:Runcong Zhao, Chengyu Cao, Qinglin Zhu, Xiucheng Ly, Shun Shao, Lin Gui, Ruifeng Xu, Yulan He
类型:Main Conference
简介:复杂叙事语境常常考验语言模型的指令遵循能力,且现有基准难以充分反映这类挑战。为此,我们提出一种免训练的框架Concise-SAE,通过仅使用自然语言指令来识别并编辑与指令相关的神经元,从而提升模型的指令遵从性,在此过程中无需标注数据。为全面评估所提方法,我们构建了 FreeInstruct(包含1,212 个示例)这一多样且贴近现实的基准,以凸显叙事密集场景中指令遵循的难点。尽管最初动机源自复杂叙事,Concise-SAE 在多项任务上仍展现出领先的指令遵循能力,且不降低生成质量。
题目:Large Language Models as Reader for Bias Detection
作者:Xuan Luo, Jing Li*, Wenzhong Zhong, Geng Tu, Ruifeng Xu*
类型:Findings
简介:识别媒体内容中的偏见对于保障信息完整性与促进社会包容性具有重要意义。现有方法多聚焦于作者视角,即通过分析文本特征推断作者意图,缺乏对读者视角的探索。本文提出利用大型语言模型(LLM)生成读者视角评论以辅助偏见检测,并在 BASIL(新闻偏见)和 BeyondGender(性别偏见)两类数据集上进行实验,实验模型为 Gemma-7B、Phi-3-3.8B、Llama3.1-8B、Llama3.1-70B 及 GPT-4。实验结果表明,读者视角评论能够显著提升开源 LLM 的检测性能,其最优效果与 GPT-4 相当。进一步分析发现,情感相关评论在偏见检测中较价值相关评论更具优势;同时,在 Llama 系列模型上的实验展现了评论选择在不同模型大小与评论组合下的稳定性。本研究尤其有利于小规模开源 LLM 的应用。
