题目:
A New Formula for Sticker Retrieval: Reply with Stickers in Multi-Modal and Multi-Session Conversation
作者:Bingbing Wang, Yiming Du, Bin Liang, Zhixin Bai, Min Yang, Baojun Wang, Kam-Fai Wong, Ruifeng Xu*
广泛应用于在线聊天中的表情包可以生动地表达用户的意图、情感或态度,现有的关于表情包检索的研究通常基于单一会话或仅仅根据对话上文的文本信息来检索表情包,忽略了历史会话的信息以及对话上文中的表情包,难以适应现实对话场景多模态和多会话的特性。
因此,本文创建了一个面向多模态和多会话对话的表情包检索数据集Multi-Chat,包含1,542个会话、50,192条语句和2,182个表情包。基于该数据集,本文提出了一种意图引导的表情包检索框架IGSR,通过意图学习来支持多模态和多会话对话中的表情包检索。具体而言,IGSR引入表情包属性以更好地利用多模态对话中的表情包信息,将其与语句结合构建一个记忆库。随后,从记忆库中提取与当前对话相关的记忆以识别对话意图,并以此为指导检索合适的表情包进行响应。
基于创建的数据集的大量实验表明,本文所提出的IGSR框架在表情包检索任务中达到了当前最先进的性能。
我们从微信这一社交媒体平台中选择了五个活跃的进行开放领域讨论的聊天群组,并收集了他们的对话。这些群组中的用户参与度高,讨论内容广泛,表情包的使用也呈现出多样化。我们在数据预处理阶段制定了严格的规范和政策,为了维护用户隐私,所有个人隐私信息都已被清除,如真实姓名、年龄和地址等,用户的ID也经过了匿名化处理。我们将每个群组的聊天内容分割成不同的会话,并保持每个会话的完整性和独立性。
我们招募了五位在多模态领域经验丰富的研究人员作为注释者,他们的任务是评估表情包的适当性并对每个表情包进行风格和意图的分类。在MultiChat数据集中,注释者对表情包风格和意图的平均Cohen's Kappa得分分别为0.919和0.832,这表明了注释之间的高度一致性。
最终Multi-Chat数据集共包含1,542个会话、50,192条语句和2,182个表情包,我们根据表情包所在位置将每个会话分成多个样本。例如,考虑包含m个话语的会话 ,其中
,其中
 可以是文本或表情包。如果
可以是文本或表情包。如果
 和
和
 是表情包,则三个样本分别是
是表情包,则三个样本分别是
 和
和
 。
划分后,
Multi-Chat
数据集共有
4851
个样本。
如上图所示,本文所提出的IGSR框架由三个主要模块组成:(1)多模态历史建模:该模块聚合多模态历史数据,使用大语言模型(LLM)创建记忆库;(2)
意图推导
:该模块将来自记忆库的相关记忆与当前会话集成,以预测用户的意图;(3)表情包检索:该模块基于预测的意图来选择表情包进行回复。
。
划分后,
Multi-Chat
数据集共有
4851
个样本。
如上图所示,本文所提出的IGSR框架由三个主要模块组成:(1)多模态历史建模:该模块聚合多模态历史数据,使用大语言模型(LLM)创建记忆库;(2)
意图推导
:该模块将来自记忆库的相关记忆与当前会话集成,以预测用户的意图;(3)表情包检索:该模块基于预测的意图来选择表情包进行回复。
为了更好地捕捉历史交互的丰富性,对于历史会话中的每个表情包,我们设计了六个属性来表示关键信息,即意图 ,风格
,风格 ,手势
,手势 ,姿势
,姿势 ,面部表情
,面部表情 和言语
和言语 。意图和风格属性来自我们的数据集,对于其他四个属性,我们使用多模态大语言模型Qwen-VL,根据设计的提示为每个表情包生成属性的描述。然后,我们将历史会话(包括话语和表情包的属性)按时间顺序馈送到大语言模型中以生成摘要,并将其存储在记忆库中:
。意图和风格属性来自我们的数据集,对于其他四个属性,我们使用多模态大语言模型Qwen-VL,根据设计的提示为每个表情包生成属性的描述。然后,我们将历史会话(包括话语和表情包的属性)按时间顺序馈送到大语言模型中以生成摘要,并将其存储在记忆库中:
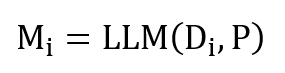
其中
 表示基于当前会话总结的包含关键信息的多个语句,P 表示用于生成记忆的大语言模型的提示:
“您的目标是总结会话
表示基于当前会话总结的包含关键信息的多个语句,P 表示用于生成记忆的大语言模型的提示:
“您的目标是总结会话
 ”。
该操作重复K次,直到会话结束,得到最终的记忆库
”。
该操作重复K次,直到会话结束,得到最终的记忆库
 。
与多模态历史建模过程类似,我们使用属性来表示当前会话中的表情包,使用text-davinci-003嵌入提取前N个相关记忆Mr = {M1,.,Mk},然后将当前会话和相关记忆馈送到文本编码器中以导出摘要和上下文表示。
其中
。
与多模态历史建模过程类似,我们使用属性来表示当前会话中的表情包,使用text-davinci-003嵌入提取前N个相关记忆Mr = {M1,.,Mk},然后将当前会话和相关记忆馈送到文本编码器中以导出摘要和上下文表示。
其中
 表示文本编码
器。
意图表示
表示文本编码
器。
意图表示
 是通过连接相关记忆表示
是通过连接相关记忆表示
 和上下文表示来获得的。
最后将组合得到的意图表示馈送到分类器中,得到每个意图类别的概率分布。
我们应用CLIP模型中预先训练的视觉Transformer作为图像编码器得到表情包的表示。
其中
和上下文表示来获得的。
最后将组合得到的意图表示馈送到分类器中,得到每个意图类别的概率分布。
我们应用CLIP模型中预先训练的视觉Transformer作为图像编码器得到表情包的表示。
其中
 是表情包表示,并且
是表情包表示,并且
 代表图像编码器。
在训练阶段,我们遵循之前的对比学习方法,并利用InfoNCE损失来训练我们的框架。给定一批
代表图像编码器。
在训练阶段,我们遵循之前的对比学习方法,并利用InfoNCE损失来训练我们的框架。给定一批
 个意图标签表示对
个意图标签表示对
 作为训练数据,其中
作为训练数据,其中
 ,我们计算文本到图像的对比损失
,我们计算文本到图像的对比损失
 和图像到文本的对比损失
如下:
其中,
和图像到文本的对比损失
如下:
其中,
 表示余弦相似性,
表示余弦相似性,
 是温度因子,表示批次大小。
我们的方法的总损失是:
是温度因子,表示批次大小。
我们的方法的总损失是:
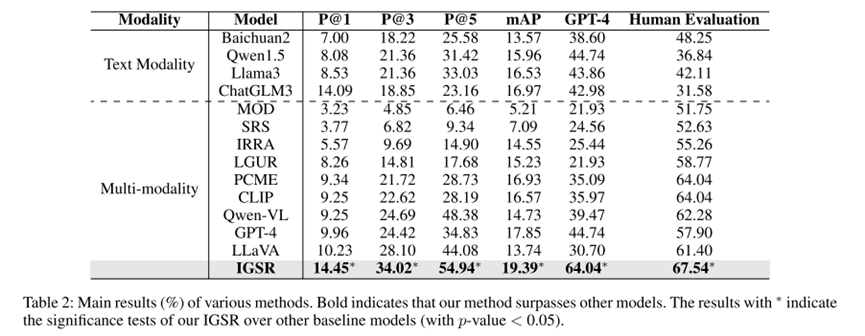
我们将IGSR框架的性能与各种基线进行了比较,如表2所示,IGSR始终优于所有基线模型,证明了其在多模态、多会话的表情包检索任务上的鲁棒性和有效性,我们还可以从该表中得出以下结论。
(1)随着Top N精度指标中N值的增加,IGSR框架的性能得到了提升,这是因为更大的N值允许更多的结果被考虑,扩大了匹配的范围并提高了找到相关标签的可能性。
(2)基于大语言模型(LLM)的文本模型在某些情况下表现优于多模态模型。这可能是因为LLM具有更复杂的网络架构和更多的参数,使其能够更好地理解和生成语言及图像描述。
(3)小型多模态模型主要关注文本和视觉内容之间的语义关系,但它们并不专门针对表情包检索场景,因此性能较差。大型多模态模型,如Qwen-VL和LLaVA,虽然表现优于小型模型,但仍然不如IGSR框架。
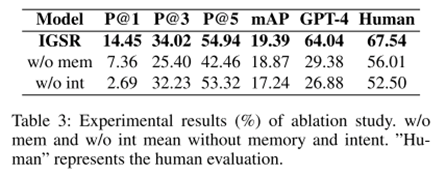
消融结果如表3所示。在所有指标下,任一消融模型的性能都比完整模型差,证明了我们方法中每个模块的必要性。值得注意的是,删除相关内存(“w/o mem”)会导致相当大的性能下降,强调了摘要在理解会话上下文中的重要性。此外,意图的移除(“w/o int”)也显著降低了性能,特别是指标P@1,这表明模型训练期间的意图预测改进了对不同属性的表情包表示的学习。
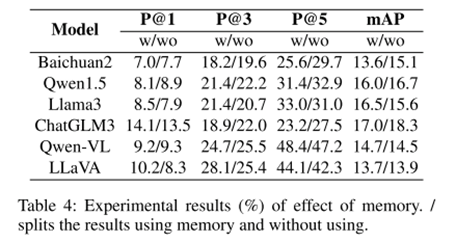
基于消融研究的结果,我们进一步探讨了记忆在表情包检索中的作用,实验结果如表4所示。不使用相关记忆时,某些模型的性能得到了提升,可能是因为长输入序列影响了大型语言模型的处理效率,而某些模型如Llama3和LLaVA在使用相关记忆时性能更佳,显示出它们在处理长文本方面的优势。
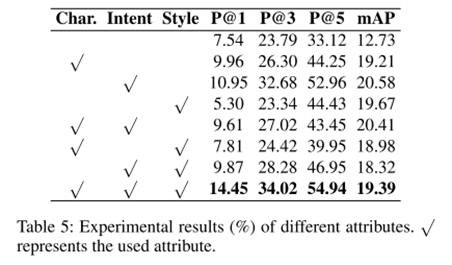
实验结果如表5所示,使用全部六种属性(意图、风格、姿势、手势、面部表情和言语)进行多模态历史建模时,表情包检索模型的性能达到最佳。此外,仅使用意图来表示表情包实现了接近使用所有属性的性能,这一结果突显了意图属性在理解和检索表情包中的重要作用。
本文创建了一个用于多模态多会话表情包检索的新数据集MultiChat,与之前仅基于当前会话检索表情包的研究不同,我们的新数据集可以覆盖更真实的场景。
基于所创建的数据集,我们提出了一个用于会话表情包检索的框架IGSR,基于多模态历史建模策略构建记忆库,并采用多任务框架同时推导意图和检索表情包。
在MultiChat数据集上进行的大量实验表明,我们提出的方法强调了意图的关键作用,并有效地利用了记忆,从而在多模态、多会话的表情包检索中实现了出色的性能。