题目:Multimodal Emotion Recognition Calibration in Conversations
作者:涂耿,熊峰,梁斌,王晖,曾曦,徐睿峰
会议:ACM MM 2024
论文链接:
https://dl.acm.org/doi/abs/10.1145/3664647.3681515
对话情绪识别(Emotion Recognition in Conversations,ERC),旨在对一段对话中的话语进行情绪分类。任务的输入是一段连续的对话,输出是这段对话中所有话语的情绪,图1给出了一个简单的示例。由于对话本身具有很多要素,话语的情绪识别并不简单等同于单个句子的情绪识别,而是需要综合考虑对话中的背景、上下文、说话人等信息,这些都是对话情绪识别任务中独特的挑战。
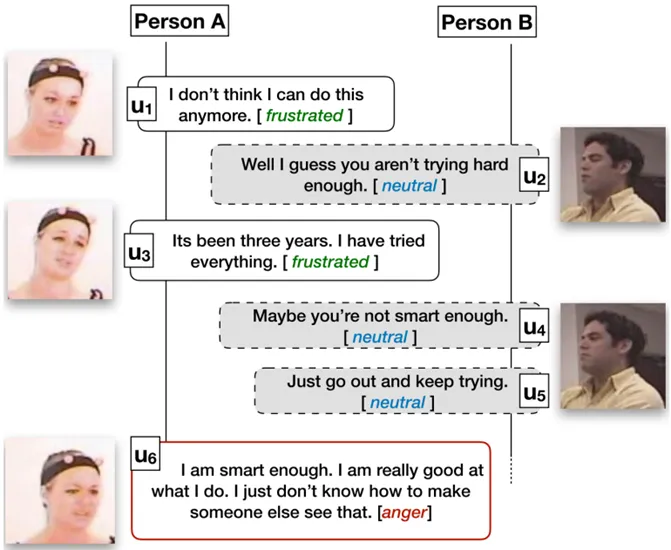
图1 对话情绪识别示例
现有的多模态对话情绪识别(Multimodal Emotion Recognition in Conversations, MERC)研究更多地聚焦于提升性能指标,而在模型可靠性方面的探索却相对不足。现有方法在移除某些模态或上下文线索后,样本的预测置信度反而增加(如图2所示)。这种反直觉现象暴露了模型在模态和上下文依赖上的不平衡,定义这类样本为不确定样本。这不仅暴露了现有方法在决策可靠性上的局限性,还违背了“信息旨在消除不确定性”的基本定义。值得注意的是,即便是一些在性能上表现更为先进的模型(如M3Net),其可靠性可能仍不及较为简单的模型(如DialogueRNN)。
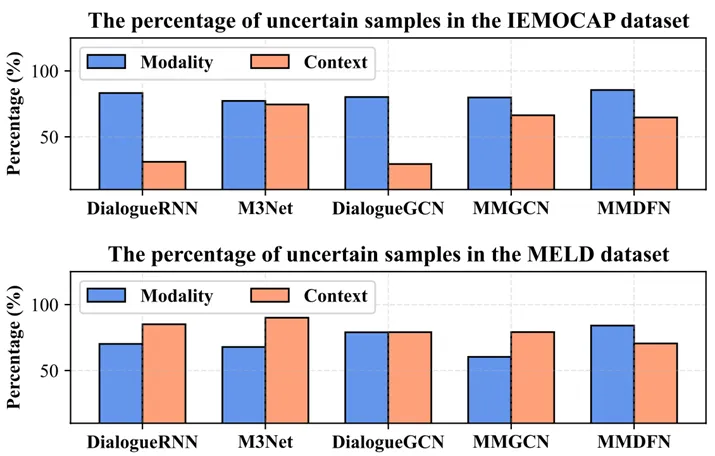
图2 动机示例
3.1总体框架:
本文提出了一种用于多模态对话情绪识别的校准框架—CMERC,旨在解决现有模型在处理情绪推断时可靠性不足的问题。框架的设计从三个关键校准方向入手(如图3所示):(1)课程学习校准(CL):引入课程学习策略,采用逐步训练的方法,将不确定样本逐步引入模型训练中。(2)混合对比学习校准(HSCL):设计了一种混合对比学习方法,通过增大不确定样本与其他样本之间的距离,增强模型对引起不确定性因素的感知能力。(3)置信度约束校准(CC):引入置信度约束机制,通过对不确定样本的惩罚,优化模型的置信度估计能力。
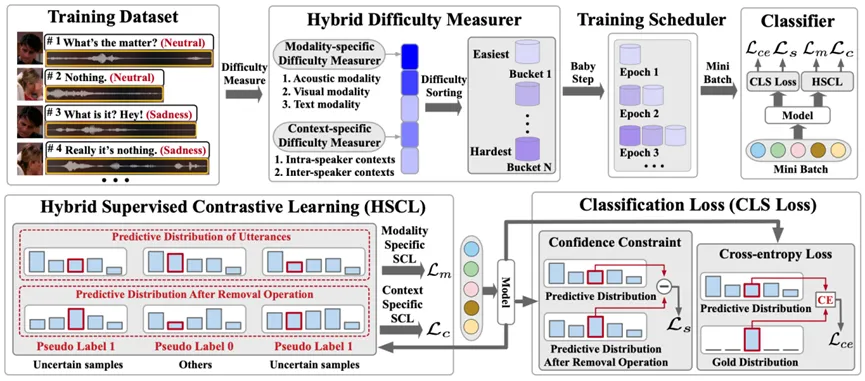
图3 CMERC整体框架图
3.2具体模型:
(1) 课程学习校准
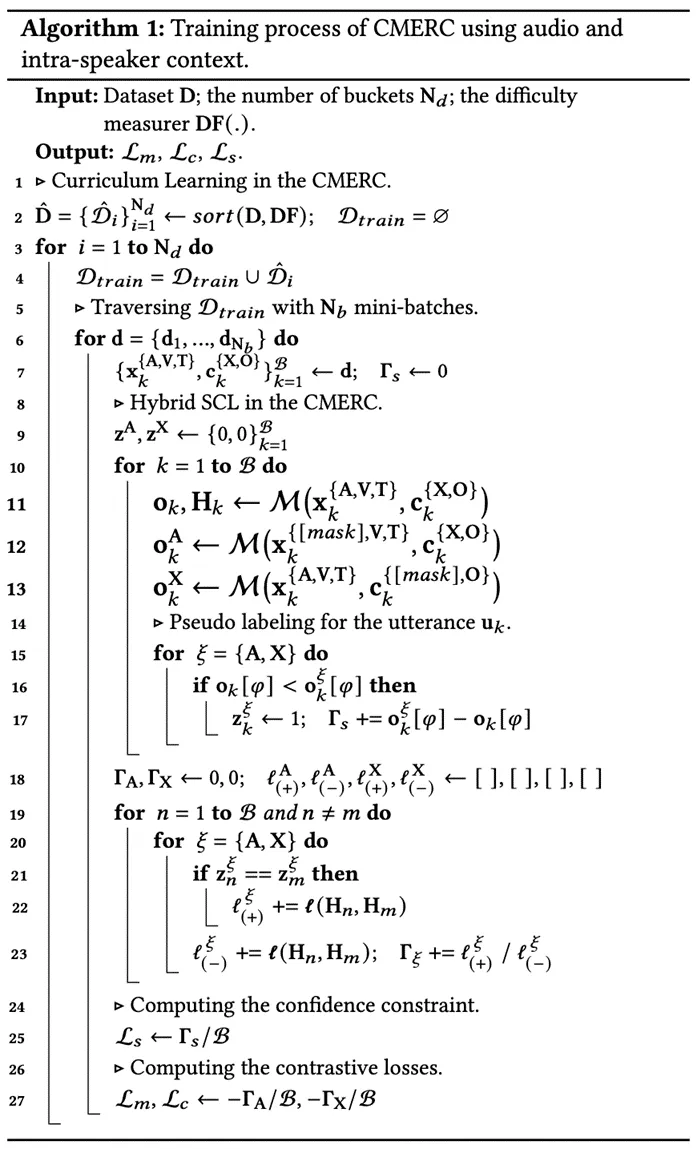
为了设计适用于MERC模型的课程,我们通过评估样本去除操作后的置信度水平,来衡量不同对话在多模态和上下文中的难度。直观来说,当MERC模型面对不确定的样本时,由于预测置信度的可靠性降低,模型往往难以做出准确的决策,这会对学习过程造成阻碍。随着对话中不确定样本数量的增加,模型的置信度愈加不稳定,从而使得情绪识别的难度也随之上升,情绪的精准把握变得更加复杂。
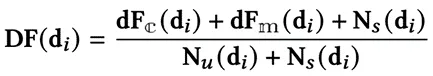
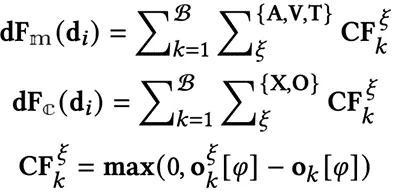
其中, 表示说话者内部和说话者间的上下文,
表示说话者内部和说话者间的上下文, 为目标类别的索引,
为目标类别的索引, 为移除某一模态或上下文后MERC模型的预测分布。
为移除某一模态或上下文后MERC模型的预测分布。 表示迷你批次
表示迷你批次 中的话语总数,而
中的话语总数,而 表示参与迷你批次的说话者总数。我们采用baby step训练调度策略,以安排对话顺序并组织训练过程,其具体流程如算法1中第1至4行所描述。
表示参与迷你批次的说话者总数。我们采用baby step训练调度策略,以安排对话顺序并组织训练过程,其具体流程如算法1中第1至4行所描述。
(2) 混合对比学习校准
理解导致样本不确定性的因素,对于提升MERC模型在训练过程中的可靠性至关重要。为此,我们提出了一种混合对比学习(HSCL)框架,该框架将针对模态和上下文的对比学习组件有机融合在一起。这一方法能够有效区分因模态或上下文信息缺失而引发的不确定性样本,并捕捉其细微的关联与差异。通过此框架,MERC模型可以深入学习训练过程中导致不确定性的根本因素,从而显著提升整体性能与效果。
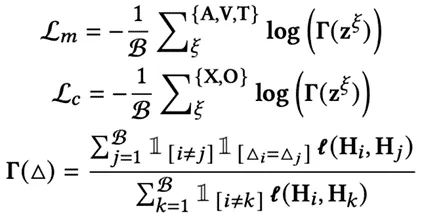
其中, 表示模型
表示模型 的隐藏表示,
的隐藏表示, 表示伪标签集,其生成过程详见算法1中的第14至17行。
表示伪标签集,其生成过程详见算法1中的第14至17行。 ,
, 为温度参数,
为温度参数, 表示余弦相似度函数。以音频模态和说话者内部上下文为例,模态和上下文特定的对比学习损失的计算过程详见算法1中的第18至27行。
表示余弦相似度函数。以音频模态和说话者内部上下文为例,模态和上下文特定的对比学习损失的计算过程详见算法1中的第18至27行。
(3) 置信度约束校准
为了提高MERC模型预测置信度的可靠性,采用一种正则化约束方法,通过计算移除操作后置信度增加的差异,作为对小批量数据的约束条件。
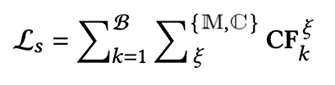
(4) 模型训练
我们通过最小化以下四项损失的总和来联合训练我们提出的框架。
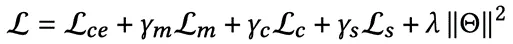
实验数据集:IEMOCAP,MELD
实验评价指标:Accuracy (Acc),Weighted-average F1 (W-F1),Expected Calibration Error (ECE),Maximum Calibration Error (MCE),Root Mean Square Calibration Error (RMSCE),Area Under the Receiver Operating Characteristic Curve (AUROC),Area Under the Precision-Recall Curve (AUPRC),Confidence Enhancement Level (CEL)
实验结果与结论:
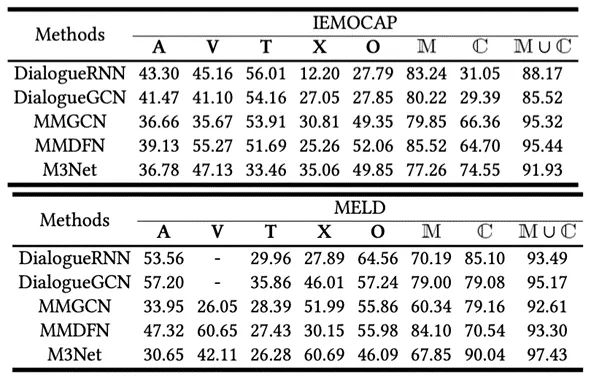
表1 测试集中不确定样本的百分比(%)
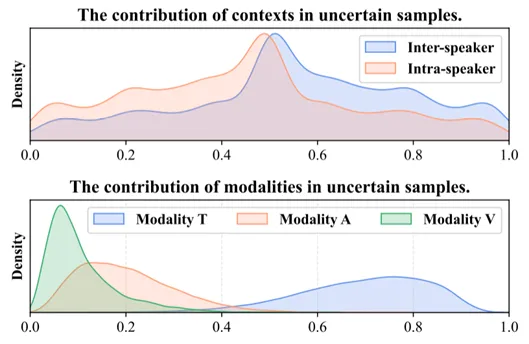
图4 IEMOCAP测试集中不确定样本的各种模态或上下文的贡献
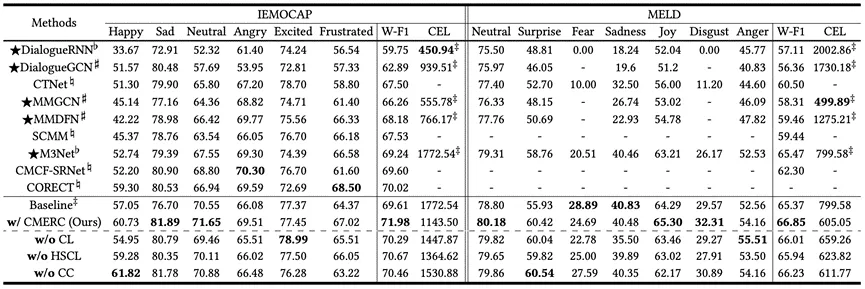
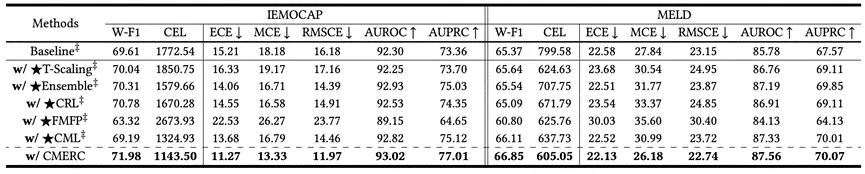
表2 IEMOCAP(6分类)和MELD上的实验结果
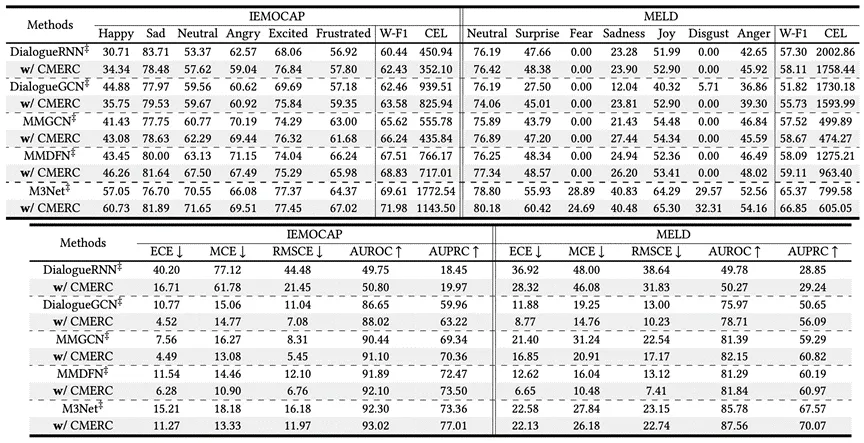
表3 IEMOCAP(6分类)和MELD上的泛化分析
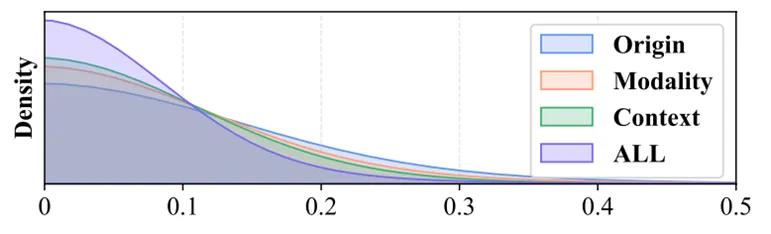
图5 CC下CF值的分布
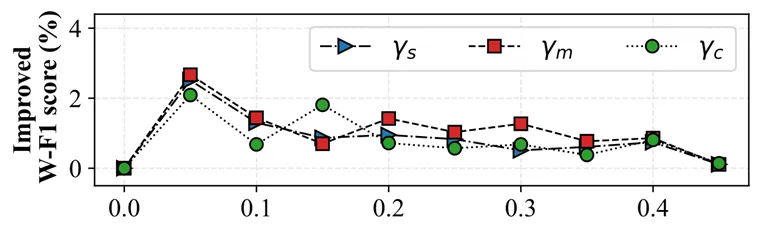
图6 IEMOCAP验证集中各种超参数的CMERC的提升W-F1
1.如表1所示,在不同的MERC模型中,不确定样本比例显著,尤其是在移除模态和上下文时超过90%,反映出MERC模型在置信度预测方面的挑战性,即便是性能更高的模型(如M3Net)也难以避免。
2.如图4所示,通过MM-SHAP方法分析了不确定样本的来源,发现其主要原因是模型过于依赖文本模态,且难以合理权衡不同上下文的影响。
3.如表2所示,CMERC在W-F1得分上的优势,分别提升了IEMOCAP和MELD数据集的得分,同时降低了CEL值,进一步证明了该方法的优越性。而且我们方法在各项指标上的表现优于其他置信度校准方法。
4.如表3所示,在不同的MERC模型上进行实验,结果显示所有方法的CEL得分一致下降,W-F1得分提高,其他置信度估计指标也表现出类似的提升,证明了CMERC在不同MERC模型中的泛化能力。
5.如图5所示,CF值分布显示较小的值对应较高的密度,这突显了CC在处理不确定样本时的有效性。
6.如图6所示,调整CMERC中损失函数的超参数后,模型性能呈先增后降的趋势,最终趋于稳定,且始终优于超参数为零的情况,体现了CMERC在不同超参数设置下的有效性。
审稿:徐睿峰
校正:王 丹