题目:Multiple Knowledge-Enhanced Interactive Graph Network for Multimodal Conversational Emotion Recognition
作者:涂耿,王隽,李真宇,陈诗炜,梁斌,曾曦,杨敏,徐睿峰
会议:Findings of EMNLP 2024
论文链接:
https://aclanthology.org/2024.findings-emnlp.222/
现有的MERC方法虽然已考虑音频、视觉和文本等多种线索,但传统的基于文本的常识知识(CSK)未能有效整合视觉情境化信息,限制了情感理解的准确性。例如,视觉CSK可以从图像中推断出,搬运沙发的人可能会小心翼翼地对待它,而这是文本CSK所无法捕捉到的细微之处(如图1所示)。因此,本研究旨在探讨如何选择和整合多种类型的常识知识,尤其是视觉常识,以提升多模态情绪识别在真实场景中的表现和实用性。

图1 动机示例
2.1设计思路:
本文提出了一种多知识增强交互图网络(MKE-IGN),通过有向图结构结合VisualCOMET和COMET中的视觉与文本常识知识(CSK),增强话语理解(如图2所示)。与传统节点表示方法不同,MKE-IGN通过边表示建模话语与CSK之间的关系,有效减少无关知识的干扰,并利用LassoNet自适应选择与情绪相关性强的CSK。在训练过程中,MKE-IGN还根据上下文对CSK进行细化,提升其在不同对话场景中的适应性。
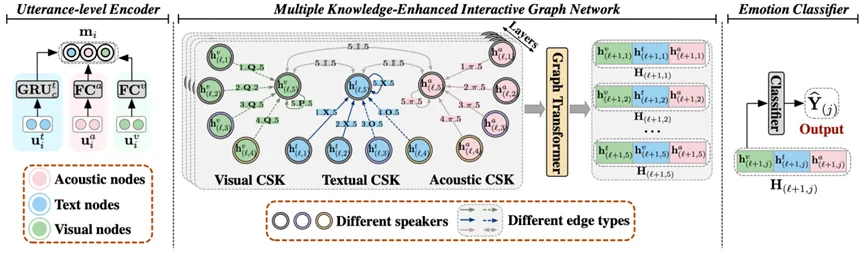
图2 MKE-IGN整体框架图
2.2具体模型:
(1) 话语级编码器
对于文本模态,我们采用双向GRU来聚合上下文信息;而对于音频和视觉模态,则使用全连接层来生成一致的固定大小的表示。
(2) 交互图网络
对于视觉“if-then”CSK 也被分为两类:
也被分为两类: 表示当前说话者的意图。而
表示当前说话者的意图。而 表示说话者的后续意图。如果i=j,节点i的关系
表示说话者的后续意图。如果i=j,节点i的关系 用P表示;如果i<j,则用Q表示节点i的关系。
用P表示;如果i<j,则用Q表示节点i的关系。
由于音频模态a缺少if-then CSK,我们使用一个全连接层 来结合节点i和j,生成
来结合节点i和j,生成 ,以此作为音频if-then CSK
,以此作为音频if-then CSK 的替代表示形式。因此,当i≤j,
的替代表示形式。因此,当i≤j, 可以用
可以用 表示。
表示。
此外,跨模态连接的关系 由一个零填充的向量
由一个零填充的向量 表示。
表示。 且
且 。
。
节点表示更新:我们采用了一个 层的图卷积变换器,用于传播交互信息,并在每一层
层的图卷积变换器,用于传播交互信息,并在每一层 更新节点表示
更新节点表示 。
。
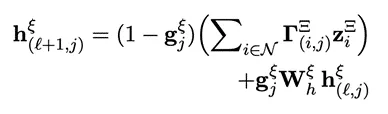
其中,N表示节点j的邻居节点索引, 是传递的消息,涉及选择后的
是传递的消息,涉及选择后的 ,记作
,记作 。通常情况下,
。通常情况下, ,但当i≠j时不一定成立。
,但当i≠j时不一定成立。 是残差连接的门控值,
是残差连接的门控值, 是用于聚集信息的注意力得分。
是用于聚集信息的注意力得分。

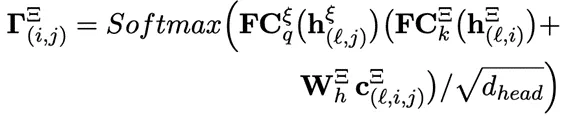
特别地,最终的输出表示为 。
。
(3) 知识选择
在基于GPT的模型(如COMET和VisualCOMET)中,表示通常以序列方式生成,最终标记的隐藏状态被视为封装整个序列语义信息的表示,用于“if-then”CSK。然而,仅依赖最后一个标记可能无法完全捕捉前面标记的语义信息,可能导致理解不完整。为了解决这一问题,将最后一个标记与之前的4个标记整合,生成5个候选项,并从中动态选择最优表示。

其中, 表示第
表示第 个候选项。由于音频CSK使用了零向量填充,因此不需要进行知识选择。
个候选项。由于音频CSK使用了零向量填充,因此不需要进行知识选择。
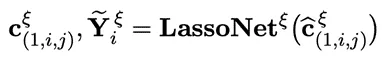
(3) 知识精炼
之前的研究通常将“if-then”CSK视为一种固定的、无梯度的表示形式,这限制了其在不同对话上下文中的适应性。为了更好地使知识与历史话语i 和当前话语j对齐,我们进行了进一步的改进。
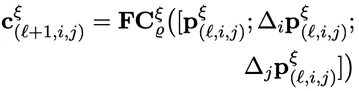
(4) 情绪分类
我们使用线性单元来预测情绪分布:
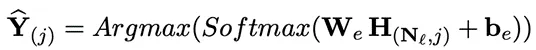
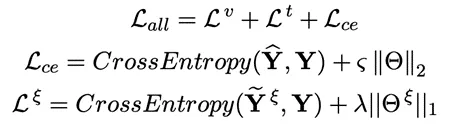
实验数据集:IEMOCAP,MELD
实验评价指标:Accuracy (Acc),Weighted-average F1 (W-F1)
实验结果与结论:
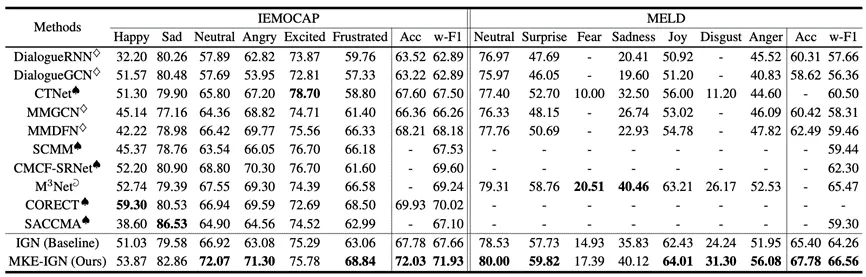
表1 IEMOCAP(6分类)和MELD上的实验结果

表2 消融研究的实验结果
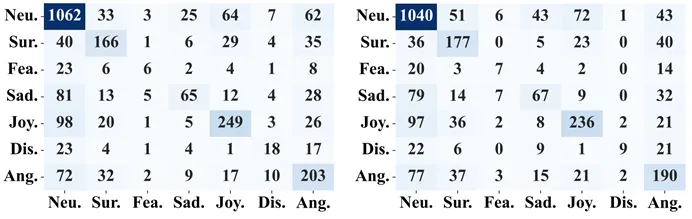
图3 在MELD数据集上的MKE-IGN(左)和移除视觉常识知识(w/o visual CSK)的MKE-IGN(右)的混淆矩阵

图4 对IEMOCAP数据集中的文本“if-then”CSK(X, O)和视觉“if-then”CSK的中间表示进行可视化(第一行),以及在知识选择后的知识表示(第二行)
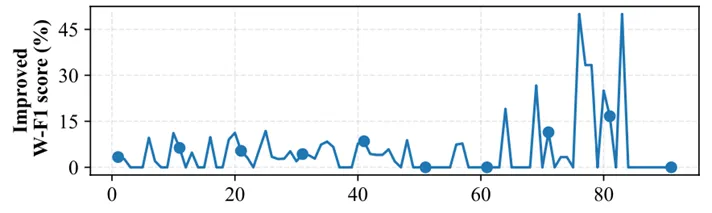
图5 在IEMOCAP数据集上,不同对话位置下MKE-IGN结合知识精炼的性能提升
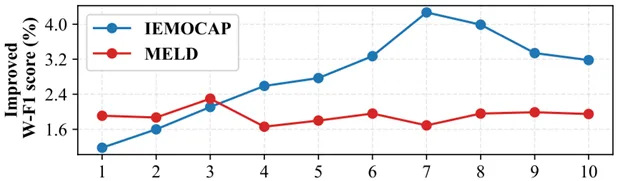
图6 MKE-IGN与基线模型在不同上下文窗口大小下的性能提升
1.如表1所示,MKE-IGN与其他模型的对比,包括先进的基于图的模型,如CORECT、CMCF-SRNet和M3Net,结果表明MKE-IGN性能优于其他模型。表2的消融实验显示了显著的性能提升。
2.如图3所示,视觉CSK在几乎所有类别样本中表现有效,但“惊讶”、“恐惧”和“悲伤”类别略有性能下降,可能是由于类别不平衡导致的。
3.为了探讨知识选择后“if-then”CSK的变化,我们通过可视化IEMOCAP数据集中的文本和视觉“if-then”CSK表示(如图4所示),发现经过知识选择处理的if-then CSK能够有效捕捉不同情感类别之间的语义区分,减轻了噪声并增强了模型在MERC任务中的情感理解能力。
4.如图5所示,在第60轮对话后,性能提升变得显著,这主要发生在对话的后期,可能是因为MERC模型倾向于优先考虑相似语义的近距离上下文,增强模型适应不同上下文的能力,可以更好地处理长对话数据。
5.如图6所示,通过调整上下文窗口大小Nω,展示了在不同数据集上模型性能的提升,较长对话(如IEMOCAP)在增大Nω后性能提升,直到达到一个临界点,而较短对话(如MELD)则在较小的窗口(Nω=3)时达到最佳效果,之后出现波动。
审稿:徐睿峰
校正:王 丹