2023年12月14日,语音与信号领域顶级学术会议ICASSP 2024 论文录用结果公布。研究团队共有五篇论文被录取。ICASSP全称 International Conference on Acoustics, Speech, and Signal Processing,在中国计算机学会推荐会议列表中被列为B类会议。会议将在2024年4月14日至19日在韩国首尔召开。论文简介如下:
标题: Enhance Generative Aspect-based Sentiment Analysis with Relation-level Supervision and Prompt
作者:杨逸凡#,张义策#,徐睿峰*
简介:方面级情感分析(ABSA)旨在识别用户的细粒度情感和观点,通常涉及四个基本情感元素:方面项、观点项、方面类别和情感极性。这一类研究的核心挑战在于有效地建模方面项和观点项之间的关系,这些关系对准确确定方面类别和情感极性至关重要。基于生成式范式的ABSA通过将情感元素转化为文本或索引序列,将ABSA任务形式化为条件生成问题,然后使用Seq2seq模型来解决这些问题。主要优势在于它能够以统一的方式处理各种ABSA问题,但也存在未充分利用方面项和观点项之间的关系的问题。本文认为显式地建模项之间的关系可以提高生成式方法的性能。具体来说,本文引入了两个新的关系模块用于生成式ABSA。第一个模块是关系监督模块(RSM)。在这个模块中,对编码器施加了一个辅助关系分类目标,以鼓励它学习融入了关系信息的表示。第二个模块是关系提示模块(RPM)。在这个模块中,首先构造了一个包含输入句子的有价值的关系信息的软提示(soft prompt),然后将其馈送到解码器中,以引导模型生成所需的目标序列。这两个模块分别增强了生成式模型在编码和解码阶段的关系建模能力。在三个基准数据集上的大量实验表明,本文提出的模块显著改善了现有生成式方法在ABSA任务中的性能。
系统框架图
标题:Enhancing Argumentative Relation Classification by Multi-Granularity Retrieval and Heterogeneous Graph Reasoning
简介:论辩关系分类(ARC)的目标是识别论点之间的关系。现有使用结构化知识来处理ARC任务的方法能够有效的前提是知识中包含了论点的主题。然而,在实际应用中,论点的主题不断涌现,提前构建一个包含所有潜在主题的结构化知识图变得不切实际。为了解决这个问题,本文从利用非结构化知识的视角来探索ARC,通过从非结构化知识中获取有关主题和论点的有用信息,以增强ARC的学习。具体而言,为了检索有关主题和论点的多样化知识,首先提出了一种为ARC设计的多粒度检索方法,通过在概念层面、概念关系层面和论点层面的密集检索来获取非结构化知识。此外,引入了一个知识感知的异构图推理器(KHGR),以更好地利用检索到的知识提高ARC性能。在三个公开可用的数据集上进行的大量实验,验证了这一模型对几个最新基线的优越性。进一步的分析表明,该方法在低资源的情况下带来了更显著的性能收益。
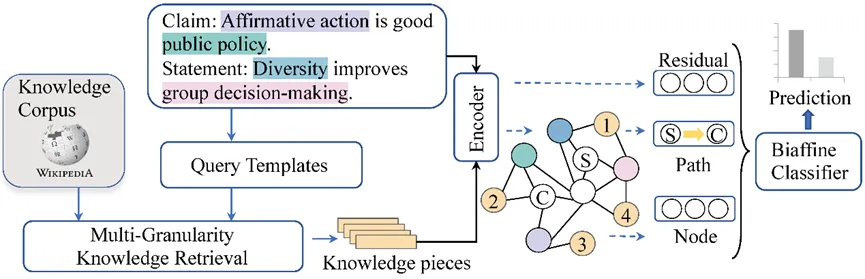
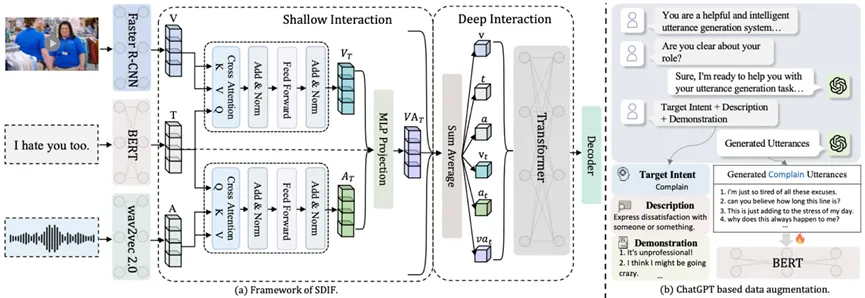
标题:SDIF-DA: A Shallow-to-Deep Interaction Framework with Data Augmentation for Multi-modal Intent Detection
作者:黄仕爵,覃立波*,王冰冰,涂耿,徐睿峰*
简介:多模态意图检测旨在利用多个模态的信息来理解用户的意图。目前的多模态意图检测任务主要面临两个挑战,分别是:(1)如何有效地对齐和融合不同模态的特征;(2)有标签的多模态意图检测数据十分有限,难以支撑充分训练。为解决上述问题,论文引入了一个带有数据增强模块的由浅到深的交互框架(SDIF-DA)。SDIF-DA利用由浅到深的交互模块,逐步有效地对齐和融合文本、视频和音频模态中的信息。具体而言,首先使用一种以文本为中心的浅交互模块来对齐不同模态的特征,然后使用基于Transformer的深交互模块来对所有的模态信息进行深度融合。接下来,提出了一种基于ChatGPT的数据增强方法来自动扩充足够的文本训练数据。实验结果表明,SDIF-DA可以通过有效地对齐和融合多模态特征以获得目前最好的性能。此外,大量的分析表明,所引入的数据扩充方法可以成功地从大型语言模型中获取相关的有效知识。
整体架构
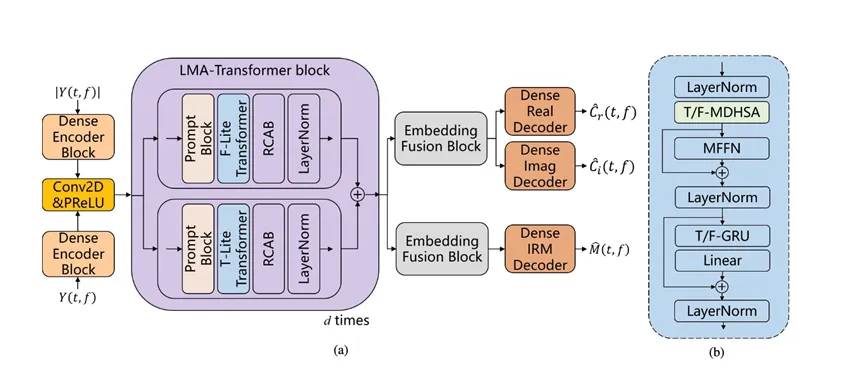
标题:Lightweight Multi-Axial Transformer with Frequency Prompt for Single Channel Speech Enhancement.
作者:梁兴伟,张泽华,王明江*,徐睿峰*
简介:语音增强技术的一个重要目标是排除环境噪音并提高语音质量和清晰度。传统的基于统计技术和数字信号处理的语音增强方法难以处理非平稳噪声。基于Transformer架构的计算负载比较大,尤其是在处理较长语音样本的时候。本文提出了一种轻量级多轴Transformer(LMA-Transformer)架构。这种架构主要关注于低计算量和低负荷的轻量化设计,并采用了沿时间轴和频率轴提取语音特征的方法。该架构的核心是时频多向卷积头自注意力模块(T/F-MDHSA)。该模块不仅降低了整体结构的计算成本,而且还增强了Transformer对局部特征的有效提取能力。本文还引入了频率提示模块,通过引入该模块来更好地增强频域特征的提取,因为频域特征在改善语音增强性能中起着至关重要的作用。频率提示模块隐式地提取需要增强的频带,并将其作为提示输入到后续网络中。在这些提示的指导下,后续网络实现了更强大的语音增强性能。与最先进的模型相比,LMA-Transformer模型在VoiceBank+Demand数据集上到达3.40 PESQ、95.8% STOI 和10.15 SSNR的优越性能。
整体框架
标题:Hybrid Attention Time-Frequency Analysis Network for Single Channel Speech Enhancement
作者:张泽华,梁兴伟,徐睿峰*,王明江*
简介:语音增强技术旨在通过降低背景噪声和减少失真来改善语音信号,进而增强语音的清晰度和整体质量。语音信号分析的核心在于其对时频的深入研究。为了提升基于神经网络的语音模型的性能,必须对时频特征进行精细化的多尺度分析。本文提出了一种混合注意力时频分析网络(HATFANet)。该模型使用双分支结构来同时估计理想比率掩模(IRM)和增强的复数频谱。在这两个分支上分别引入了一个专为时频分析而量身定制的新型混合注意力模块HAB(Hierarchical Attention Blocks),以此来充分挖掘时频的特征信息。这个方法的独特之处在于其着重强调分析时频的多尺度视角,即在五个尺度上进行分析:局部、全局、窗口间、通道和窗口内。通过多尺度分析方法,模型能够全面捕捉到语音中的时间相关性和频谱特性。为了进一步提升性能,本文在编码器和解码器之间叠加了四个HAB。这个设计有效地增强了特征提取过程,使之能从基础的浅层特征逐渐过渡到更加复杂的深层特征。不仅丰富了特征的层次,也增强了特征的上下文关联性。实验结果显示了HAB在不同注意力尺度上的重要性。在Voice Bank + DEMAND数据集上,HATFANet 达到了3.37 PESQ、95.8% STOI 和 10.15 SSNR的最先进的结果。