投稿作者:涂耿 徐睿峰
对话情绪识别(Emotion Recognition in Conversations,ERC),旨在对一段对话中的话语进行情绪分类。任务的输入是一段连续的对话,输出是这段对话中所有话语的情绪,图1给出了一个简单的示例。由于对话本身具有很多要素,话语的情绪识别并不简单等同于单个句子的情绪识别,而是需要综合考虑对话中的背景、上下文、说话人等信息,这些都是对话情绪识别任务中独特的挑战。
对话情绪识别可广泛应用于各种对话场景中,如社交媒体中评论的情感分析、人工客服中客户的情绪分析等。此外,对话情绪识别还可应用于聊天机器人中,实时分析用户的情绪状态,实现基于用户情感驱动的回复生成。本文介绍ACL 2023中的八篇关于对话情绪识别的论文:
[1]Zheng, W., Yu, J., Xia, R., & Wang, S. (2023, July). A Facial Expression-Aware Multimodal Multi-task Learning Framework for Emotion Recognition in Multi-party Conversations. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 15445-15459).
[2]Zhang, X., & Li, Y. (2023, July). A Cross-Modality Context Fusion and Semantic Refinement Network for Emotion Recognition in Conversation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 13099-13110).
[3]Zhang, D., Chen, F., & Chen, X. (2023, July). DualGATs: Dual Graph Attention Networks for Emotion Recognition in Conversations. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 7395-7408).
[4]Shi, T., & Huang, S. L. (2023, July). MultiEMO: An Attention-Based Correlation-Aware Multimodal Fusion Framework for Emotion Recognition in Conversations. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 14752-14766).
[5]Li, Z., Zhou, Y., Liu, Y., Zhu, F., Yang, C., & Hu, S. (2023, July). QAP: A Quantum-Inspired Adaptive-Priority-Learning Model for Multimodal Emotion Recognition. In Findings of the Association for Computational Linguistics: ACL 2023 (pp. 12191-12204).
[6]Yang, H., Gao, X., Wu, J., Gan, T., Ding, N., Jiang, F., & Nie, L. (2023, July). Self-adaptive Context and Modal-interaction Modeling For Multimodal Emotion Recognition. In Findings of the Association for Computational Linguistics: ACL 2023 (pp. 6267-6281).
[7]Hu, D., Bao, Y., Wei, L., Zhou, W., & Hu, S. (2023). Supervised Adversarial Contrastive Learning for Emotion Recognition in Conversations. In Findings of the Association for Computational Linguistics: ACL 2023 (pp. 10835-10852).
[8]Tu, G., Liang, B., Mao, R., Yang, M., & Xu, R. (2023, July). Context or Knowledge is Not Always Necessary: A Contrastive Learning Framework for Emotion Recognition in Conversations. In Findings of the Association for Computational Linguistics: ACL 2023 (pp. 14054-14067).
二、基于面部表情感知的多模态多任务学习框架在多方对话中的情绪识别
Facial Expression-Aware Multimodal Multi-task Learning Framework for Emotion Recognition in Multi-party Conversations
近年来,多方对话中的多模态情绪识别(Multimodal Emotion Recognition in Multiparty Conversations, MERMC)引起了人们的广泛关注。由于多方对话中视觉场景的复杂性,以往大多数MERMC研究主要关注文本和音频模态,而忽略了视觉信息。最近,一些工作提出了提取人脸序列作为视觉特征,并表明了视觉信息在MERMC中的重要性。然而,在给定的话语中,以前的方法提取的人脸序列可能包含多个人的人脸,这将不可避免地给真实说话人的情绪预测带来噪声。例如,在图2-1中,有两个人,Joey和Chandler,他们的面部表情截然不同,即:厌恶和愤怒。
本文提出了(Facial expression-aware MultimodalMulti-Task learning,FacialMMT)框架。为了获得每个话语中真实说话人的人脸序列,第一阶段引入了一种流水线方法来进行多模态人脸识别和无监督聚类,然后进行人脸匹配。对于提取的面部序列,第二阶段采用辅助帧级面部表情识别任务来生成面部序列中每个帧的情绪分布,然后使用跨模态变换器将情绪感知视觉表示与文本和声学表示相集成,用于多模态情绪识别。
FacialMMT的总体框架如图2-2所示。如左侧所示,第一阶段基于三个步骤提取真实说话者的面部序列:多模态人脸识别、无监督聚类和面部匹配。第二阶段如右侧所示,介绍了(Multimodal facial expression-aware multi-task learning model,MARIO),包括单模态特征提取、情感感知视觉表示和多模态融合。
本文使用预训练模型TalkNet来进行说话人检测。对于短时或复杂场景的视频,我们进一步设计了多模态规则,包括嘴巴张合频率、不同人嘴巴在帧间的动作,以及嘴巴动作与音频信号的对齐。
本文应用无监督聚类算法InfoMap来识别序列中的人脸聚类数量,首先使用K-最近邻算法来构建所有潜在说话者人脸的图,其次计算人脸之间的相似度,并使用归一化作为边的权重,然后进行随机行走,以生成不同的人脸序列。最后,我们对人脸序列进行分层编码,并最小化最小平均编码长度以获得聚类结果。
基于多模态人脸识别中提取的原始人脸序列,为每个主角手动选择20张不同的人脸图像,并将这120张图像作为人脸库。接下来,使用预训练模型ResNet-50来提取不同人脸聚类中图像的视觉特征。通过计算其视觉表示之间的余弦相似性,将每个人脸聚类中的图像与库中六个主角的图像进行匹配。
给定话语
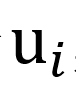 ,从三种模态
,从三种模态
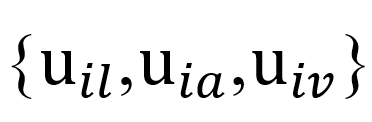 中提取单模态特征,以获得文本、音频和视觉表示,如下所示:
文本:
为了有效地利用对话上下文和说话者的情绪动态,将输入话语及其所有上下文话语连接起来作为输入,并将其输入到预先训练的语言模型(例如,
BERT
)中进行微调。然后,取出第一个标记的隐藏表示作为文本表示
中提取单模态特征,以获得文本、音频和视觉表示,如下所示:
文本:
为了有效地利用对话上下文和说话者的情绪动态,将输入话语及其所有上下文话语连接起来作为输入,并将其输入到预先训练的语言模型(例如,
BERT
)中进行微调。然后,取出第一个标记的隐藏表示作为文本表示
 ,其中
,其中
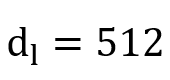 。
音频:基于在Librispeech-960h数据集上预训练的Wav2vec2.0模型来获得单词级音频表示,用
。
音频:基于在Librispeech-960h数据集上预训练的Wav2vec2.0模型来获得单词级音频表示,用
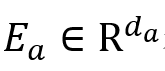 表示,其中
表示,其中
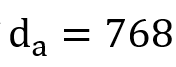 。
视觉:给定输入话语的真实说话人的面部序列,使用在CASIA-WebFace数据集上预训练的InceptionResNetv1模型来获得帧级视觉表征
。
视觉:给定输入话语的真实说话人的面部序列,使用在CASIA-WebFace数据集上预训练的InceptionResNetv1模型来获得帧级视觉表征
 ,其中L是面部序列长度,
,其中L是面部序列长度,
 。
。
-
一种辅助帧级面部表情识别任务,即:Dynamic Facial Expression Recognition(DFER):
假设D是DFER任务的另一组样本。每个样本
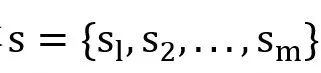 包含m个人脸的序列。DFER的目标是预测标签序列
包含m个人脸的序列。DFER的目标是预测标签序列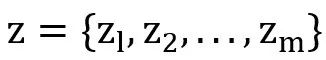 ,其中每个标签 ,其中每个标签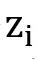 属于C个预定义的面部表情之一(即:情绪类别)。 属于C个预定义的面部表情之一(即:情绪类别)。
-
如图2-2右上角所示,在Ms-Celeb-1M数据集上使用了一个预训练模型SwinTransformer,以获得人脸序列中每个帧的表示,如下所示:
其中,是生成的面部特征。接下来,将输入到用于面部表情识别的多层感知器(MLP)层中。在训练阶段,使用交叉熵损失来优化DFER任务的参数。
-
由于基于
DFER
辅助模块所获得的情绪感知的视觉表示是将每帧的预测情绪转换为
One-hot
向量,并将其与原始表示合并为帧级视觉表示。然而,从
Argmax
函数导出的
One-hot
向量是不可微的,为了解决这个问题,本文应用
Gumbel-Softmax
以获得每个帧的近似情绪分布。
其中,
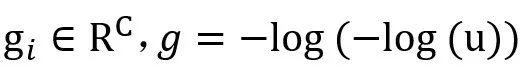 是从Gumbel分布中采样的噪声。
是从Gumbel分布中采样的噪声。
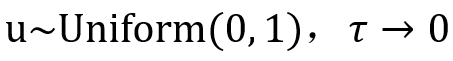 。
此外,为了减轻情绪模糊帧的噪声,本文设计了一种门控机制来动态控制人脸序列中每个帧对MERMC任务的贡献。具体来说,第i帧的情情绪清晰度可以计算为
。
此外,为了减轻情绪模糊帧的噪声,本文设计了一种门控机制来动态控制人脸序列中每个帧对MERMC任务的贡献。具体来说,第i帧的情情绪清晰度可以计算为
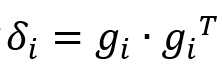 。基于此,可以获得人脸序列中所有帧的情绪清晰度。然后,我们将
。基于此,可以获得人脸序列中所有帧的情绪清晰度。然后,我们将
 应用于原始视觉表示
应用于原始视觉表示
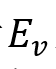 ,以过滤掉情绪模糊的帧,即:
,以过滤掉情绪模糊的帧,即: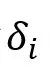 小于阈值。最后,将过滤后的视觉表示 小于阈值。最后,将过滤后的视觉表示
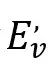 和所有帧
和所有帧
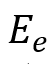 的情绪分布合并起来,以获得情绪感知视觉表示
的情绪分布合并起来,以获得情绪感知视觉表示
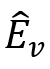 。
。
-
将
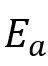 和
输入到两个独立的自注意Transformer层,以对音频特征和视觉特征内的模态内交互进行建模。
和
输入到两个独立的自注意Transformer层,以对音频特征和视觉特征内的模态内交互进行建模。
-
本文应用跨模型Transformer层,将文本和音频模态交替作为查询向量,然后将它们合并起来以获得文本-音频融合表示
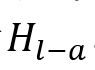 。类似地,然后将其与视觉模态融合,以获得下面的话语级文本-音频-视觉融合表示
。类似地,然后将其与视觉模态融合,以获得下面的话语级文本-音频-视觉融合表示
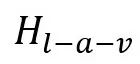 。最后,
被输入到用于情绪分类的Softmax层,标准交叉熵损失用于优化MERMC任务的参数:
。最后,
被输入到用于情绪分类的Softmax层,标准交叉熵损失用于优化MERMC任务的参数:
实验数据集:MELD for MERMC,Aff-Wild2 for DFER
实验评价指标:Weighted average F1-score (MERMC),Macro F1-score (DFER)
表2-1 MERMC任务在MELD数据集上的比较结果
-
关注当前说话人的话语,并对参与者的情绪流的情感惯性进行建模,其中,
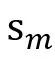 表示话语 表示话语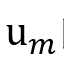 的说话人。 的说话人。
-
-
为了解决固定窗口方法平等对待窗口中的话语的问题,计算
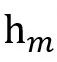 和 和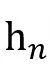 的相对位置权重RP,最后,应用元素乘积来获得LCA=sigmoid(RP)×SA,它结合了局部上下文和说话人信息。
的相对位置权重RP,最后,应用元素乘积来获得LCA=sigmoid(RP)×SA,它结合了局部上下文和说话人信息。
-
首先,均衡每个话语
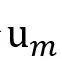 的声学特征 的声学特征 ,文本特征 ,文本特征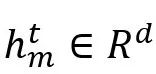 ,以及跨模态特征 ,以及跨模态特征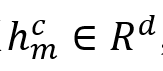 ,然后,将它们连接在一起,考虑不同模态的不同贡献,以关注重要模态。在给定的时间,输入特征 ,然后,将它们连接在一起,考虑不同模态的不同贡献,以关注重要模态。在给定的时间,输入特征 ,其中,K是模态的数量。每个模态的得分计算如下: ,其中,K是模态的数量。每个模态的得分计算如下:
-
其中,注意力得分
 ,K=3。最终的多模态特征
,K=3。最终的多模态特征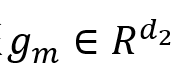 ,结合 ,结合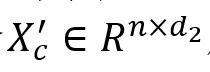 后,生成如下: 后,生成如下:
-
-
-
-
如图3-2所示,为了探索对话中话语之间的语义关系,提出了一种新的语义信息提炼模型。它主要包括两个阶段:关系语义图的构建和语义信息的精化。将定义良好的语义图输入到两层RGCN中,以计算话语的语义特征及其交互关系。然后通过语义图Transformer进一步提取全局语义信息
-
为了建立局部话语之间的语义关系,并捕捉说话人之间和说话人内部的效果,基于对话语义感知依赖性定义了一个语义图
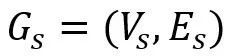 。每个话语由一个节点表示,不同的连接边表示有向关系(过去和未来), 。每个话语由一个节点表示,不同的连接边表示有向关系(过去和未来),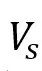 表示一组话语节点, 表示一组话语节点, 是一组关系,表示话语之间的语义相似性。
是一组关系,表示话语之间的语义相似性。
-
首先在人工注释的对话语料库上预训练话语解析器,然后,使用这个预先训练好的解析器来预测ERC数据集中存在的对话中的话语依赖性。因此,对于每个对话,
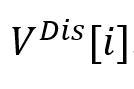 或 或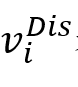 表示对应于话语 表示对应于话语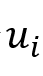 的节点,该节点用对应的特征表示 的节点,该节点用对应的特征表示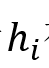 初始化。如果存在具有特定类型的从到 初始化。如果存在具有特定类型的从到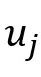 的连边,则边 的连边,则边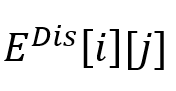 或 或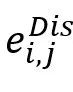 被赋予依赖类型 被赋予依赖类型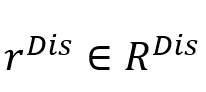 。 。
-
对于给定节点
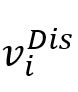 ,DisGAT将其相邻节点的信息聚合如下:
,DisGAT将其相邻节点的信息聚合如下:
-
-
其中,
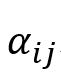 表示从节点到其邻居 表示从节点到其邻居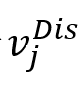 的边权重,sm表示Softmax函数,LRL表示LeakyReLU激活函数。
的边权重,sm表示Softmax函数,LRL表示LeakyReLU激活函数。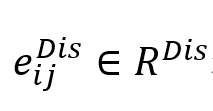 表示与节点和之间的话语依赖类型相对应的一个热编码(在训练期间固定), 表示与节点和之间的话语依赖类型相对应的一个热编码(在训练期间固定),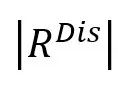 表示话语依赖类型的数量。 表示话语依赖类型的数量。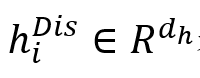 表示DisGAT更新后,节点的隐含表征。所有节点的隐含表征为 表示DisGAT更新后,节点的隐含表征。所有节点的隐含表征为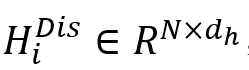 ,其计算过程如下: ,其计算过程如下:
-
-
-
SpkGAT模块在说话人依赖图
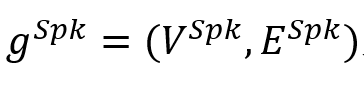 上执行消息传播,以结合说话人感知的上下文信息。 上执行消息传播,以结合说话人感知的上下文信息。
-
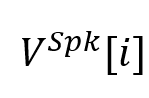 或 或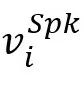 表示对应于话语的节点,该节点用对应的特征表示 表示对应于话语的节点,该节点用对应的特征表示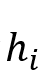 初始化。 初始化。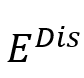 是描述说话人以及节点(话语)之间的时间依赖性的邻接矩阵,这些说话人依赖类型包括:Self-Past, Self-Future, Inter-Past, Inter-Future, 和SelfLoop (这些类型统称为 是描述说话人以及节点(话语)之间的时间依赖性的邻接矩阵,这些说话人依赖类型包括:Self-Past, Self-Future, Inter-Past, Inter-Future, 和SelfLoop (这些类型统称为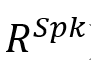 )。对于任何和 )。对于任何和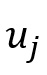 ,如果它们满足说话者依赖类型 ,如果它们满足说话者依赖类型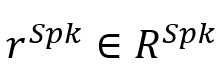 , ,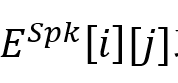 或 或 。在说话人依赖图构建后,类似地,SpkGAT的计算过程如下: 。在说话人依赖图构建后,类似地,SpkGAT的计算过程如下:
-
-
为了从话语结构和说话人感知上下文中捕获不同的信息,引入了一个微分正则化子,它鼓励DisGAT和SpkGAT模块的更新表示之间的差异。正则化子的公式如下:
-
-
然后,为了在两个模块之间有效地交换相关信息,采用了相互交叉注意力作为桥梁。计算过程公式如下:
-
-
为了在多个连续层上迭代精化和交换话语结构信息和说话人感知上下文信息,初始层的计算过程如下:
-
每个文本话语
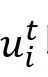 以的说话人的名字为前缀,使得说话人信息可以被有效地编码。然后,第i个话语的输入序列由三个片段组成,以包含上下文信息,即:历史话语 以的说话人的名字为前缀,使得说话人信息可以被有效地编码。然后,第i个话语的输入序列由三个片段组成,以包含上下文信息,即:历史话语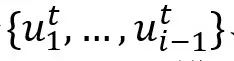 、当前话语和未来话语 、当前话语和未来话语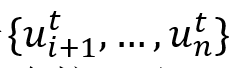 。这三个片段被合并输入到预训练模型RoBERTa和随后的全连接层中,然后,首位标志[CLS]的隐含状态被用作话语的256维度的上下文表征 。这三个片段被合并输入到预训练模型RoBERTa和随后的全连接层中,然后,首位标志[CLS]的隐含状态被用作话语的256维度的上下文表征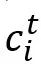 。 。
-
本文使用OpenSMILE为每个话语音频提取6373维的特征表示,然后采用全连接层为每个输入音频
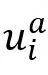 获得512维的特征 获得512维的特征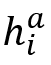 。在单峰音频特征提取之后,我们使用DialogueRNN来捕获每个音频剪辑的256维的上下文化音频特征 。在单峰音频特征提取之后,我们使用DialogueRNN来捕获每个音频剪辑的256维的上下文化音频特征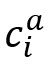 。 。
-
本文提出了一种名为VisExtNet的新型视觉特征提取器,它由MTNN和在VGGFace2上预训练的ResNet-101组成。VisExtNet的体系结构如图5-1所示。具体地,对话语视频片段的20个帧执行视觉特征提取,每个帧首先被发送到MTNN中,以检测所有说话人的面部,然后通过ResNet-101,以提取视觉特征。这些特征的串联被视为该帧的视觉表示。之后在帧轴上平均汇集所有帧的输出特征,以获得1000维视觉特征向量
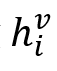 。与音频上下文建模类似,在提取视觉特征后,使用另一个DialogueRNN来学习每个视频片段的256维度的上下文视觉表征。 。与音频上下文建模类似,在提取视觉特征后,使用另一个DialogueRNN来学习每个视频片段的256维度的上下文视觉表征。
-
为了减轻对少数和语义相似情绪进行分类的困难,在Focal比度损失的基础上,通过引入样本权重项和focusing参数,提出了一种新的损失函数,称为样本加权焦对比度(Sample Weighted Focal Contrastive, SWFC)损失,以在训练阶段更加重视难以分类的少数类,并使具有不同情绪标签的样本对相互排斥,以最大化类间距离,从而更好地区分语义相似的情绪。SWFC损失定义如下:
-
本文利用Soft-HGR损失[2]来最大化从MultiAttn中提取的多模态融合文本、音频和视觉特征之间的相关性。Soft-HGR损失定义如下:
-
本文还采用交叉熵损失来衡量预测概率和真实标签之间的差异:
-
SWFC损失、Soft-HGR损失和交叉熵损失的线性组合被用作全损失函数:
-
由于当前话语的情绪可能是基于较长时间前提出的另一个话题,即:远距离的情绪依赖关系。所以设计了全局上下文表示子模块来对这种场景进行建模。对于不同模态的对话特征
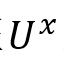 ,其中 ,其中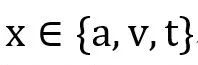 和 和 ,然后通过多头注意力机制获得的中间表示通过常用的残差级联、层归一化和前馈层,获得该子模块的最终输出 ,然后通过多头注意力机制获得的中间表示通过常用的残差级联、层归一化和前馈层,获得该子模块的最终输出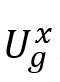 ,即: ,即: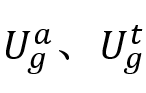 和 和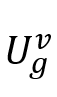 。 。
-
由于当前话语的情绪可能会受到相邻话语的影响,这是一种在局部范围内发生的短距离情绪依赖。所以设计了局部上下文表示模块。对于任何模态输入
 ,通过以下公式计算局部上下文表示特征 ,通过以下公式计算局部上下文表示特征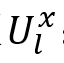 : :
-
对于本身包含足够信息的话语,上下文表征可能会引入额外的噪声。所以设计了直接映射子模块,通过线性层直接提取每个话语的信息:
-
-
对于简单话语,和三种模态
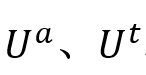 和 和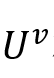 相互补充的并且每个模态包含相对等量的信息的理想情况,设计了全交互子模块来直接连接三个多模态特征,并使用线性层提取多模态特征: 相互补充的并且每个模态包含相对等量的信息的理想情况,设计了全交互子模块来直接连接三个多模态特征,并使用线性层提取多模态特征:
-
对于稍微复杂的话语,由于缺乏关键信息或噪声的混合,不同模态的贡献各不相同。所以设计了部分交互子模块,通过多样化的模态交互来缓解这个问题。具体地,组合
 和 和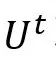 以获得 以获得 和 和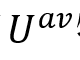 特征。 特征。
-
对于难度较大的话语,设计了有偏交互子模块。在互动过程中,首先将文本作为主要模态,其他作为辅助模态,以减轻文本的信息损失。其次,使用带有局部注意力掩码的小型Transformer来进一步利用来自相邻话语的更多模态信息。具体地,有偏交互子模块将分别与和合并以获得
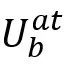 和 和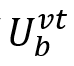 。这两个特征将在通过它们各自的线性层之后被合并。随后,应用具有局部注意力掩码的 Transformer来合并来自局部缩放的多模态特征。掩蔽注意力的操作可以公式化如下:
其中,对于这部分的局部注意掩码,定义了依赖上下文和二元向量 。这两个特征将在通过它们各自的线性层之后被合并。随后,应用具有局部注意力掩码的 Transformer来合并来自局部缩放的多模态特征。掩蔽注意力的操作可以公式化如下:
其中,对于这部分的局部注意掩码,定义了依赖上下文和二元向量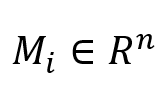 长度的参数 长度的参数 和 和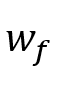 。最后,得到了局部注意掩码 。最后,得到了局部注意掩码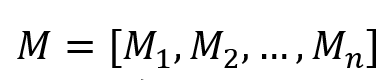 ,其中 ,其中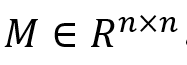 。最终的多模态特征 。最终的多模态特征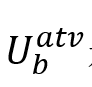 是在具有局部注意力掩码的Transformer之后获得的。 是在具有局部注意力掩码的Transformer之后获得的。
-
参考之前的工作,将预训练模型Roberta-large在训练集上进行微调,用于话语级情绪分类,并在训练我们模型时冻结其参数。形式上,给定话语输入
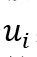 ,编码器的最后一个隐藏层中[CLS]令牌的输出用于获得具有维度 ,编码器的最后一个隐藏层中[CLS]令牌的输出用于获得具有维度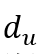 的话语表示 的话语表示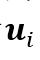 。 。
-
SACL-LSTM的网络结构由双向长短期记忆模块Dual-LSTM和情绪分类器组成。Dual-LSTM在提取文本特征后,用于捕获对话的情境和说话人感知上下文特征。其中说话人感知特征
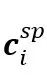 的计算如下:
此外,情境感知特征 的计算如下:
此外,情境感知特征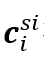 被定义为: 被定义为:
-
最后,将情境感知特征和说话人感知特征合并起来,形成每个话语的上下文表征,即:
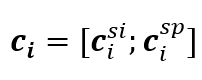 。 。
-
最后,根据上下文表征,采用情绪分类器预测每个话语的情绪标签。
|