2023年10月8日,EMNLP 2023会议(The 2023 Conference on Empirical Methods in Natural Language Processing) 论文录用结果公布。研究团队共有九篇长文获录用,其中五篇获主会录用,四篇获Findings of EMNLP录用。EMNLP是自然语言处理领域的国际顶级学术会议,在中国计算机学会推荐会议列表为B类会议,由国际计算语言学会(ACL)主办。EMNLP 2023 将于2023年12月6日-12月10日在新加坡召开。
标题:Target-to-Source Augmentation for Aspect Sentiment Triplet Extraction
作者:Yice Zhang, Yifan Yang, Meng Li, Bin Liang, Shiwei Chen, Ruifeng Xu*
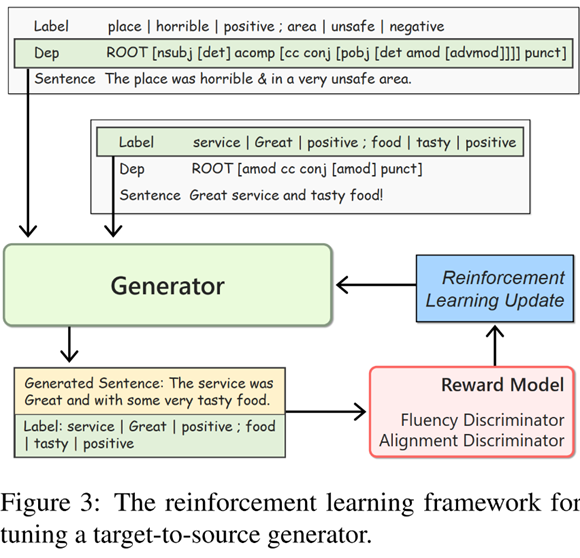
简介:本文针对方面情感三元组抽取任务,提出了一种生成式数据增强方法,以缓解该任务中的数据稀缺问题。传统的数据增强方法通过修改现有样本以产生新的样本,这样得到样本的多样性有限。与此不同,我们设计了一个根据标签和句法模板来生成句子的生成器。利用这个生成器,我们可以通过混合不同样本中的标签和句法树,从而合成出大量且多样化的样本。为了确保生成句子的质量,我们还引入了流利度判别器和一致性判别器,分别对句子的流利度和标签一致性进行评价。一方面,使用它们为生成的句子提供反馈,进而通过强化学习的框架来优化生成器;另一方面,借助它们对生成样本进行进一步的筛选。大量的实验表明这一增强方法可以显著提升现有方法的性能,并优于以往的增强方法。
标题:Stance Detection on Social Media with Background Knowledge
作者:Ang Li, Bin Liang, Jingqian Zhao, Bowen Zhang, Min Yang, Ruifeng Xu*
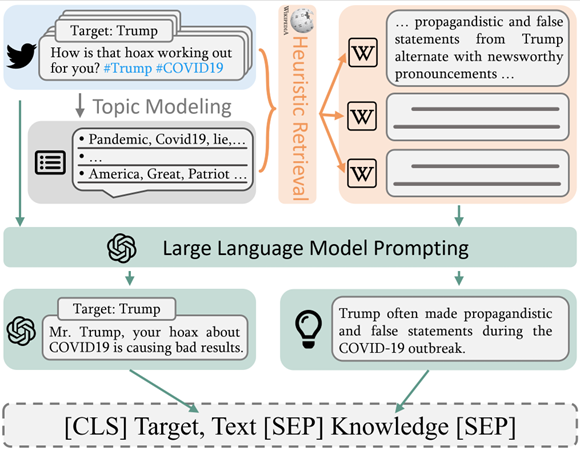
简介:在现实生活中,人们在表达对于特定目标立场时通常对具有该目标背景知识,而这些背景知识通常不会出现在上下文中,这使得直接判断文本立场变得较为困难。因此,获取和利用目标相关的背景知识来对于文本立场检测任务非常重要。本文根据语言学背景,将背景知识分为两类:经验知识(episodic knowledge)和语境知识(discourse knowledge),并提出了一种新的知识增强立场检测框架(KASD)。通过爬取与每个立场目标相关的维基百科页面作为知识库,并基于主题建模和大语言模型提示学习提出一种启发式检索算法,以获取样本需要的经验知识。同时,本文使用大语言模型提示学习来解释文本中的别名、缩写、话题标签、网络用语和代词等,用于获取样本需要的语境知识。最后,结合获取的经验知识和语境知识来对立场检测任务进行知识增强。在四个基准数据集的实验结果表明,KASD在目标内立场检测和零样本立场检测任务上取得了最优的结果。
标题:A Training-Free Debiasing Framework with Counterfactual Reasoning for Conversational Emotion Detection
作者:Geng Tu, Ran Jing, Bin Liang, Min Yang, Kam-Fai Wong, Ruifeng Xu*
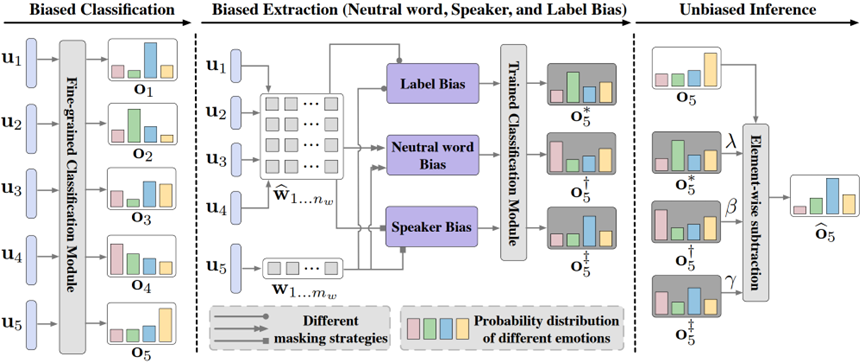
简介:现有的对话情绪识别(ERC)数据集通常存在着意外的数据偏差,包括标签偏差以及说话人和中性词偏差。然而,以往的研究通常集中于捕捉依赖于上下文和说话者的关系,忽视了数据的意外偏差,这妨碍了ERC的泛化和公平性。为此,本文提出了一个无需额外训练的去偏框架(TFD)。为了确保与各种ERC模型的兼容性,TFD不会平衡数据或修改模型结构。相反,TFD通过生成对立的话语和上下文来从模型中提取偏差,并使用简单但经验上强大的逐元素减法运算来减轻偏差。在三个公共数据集的大量实验表明,TFD有效地提高了不同ERC模型的泛化能力和公平性。
题目:Set Learning for Generative Information Extraction
作者:Jiangnan Li, Yice Zhang, Bin Liang, Kam-Fai Wong, Ruifeng Xu*
简介:最近的工作致力于在信息抽取中应用序列到序列的模型,因为它有潜力以统一的方式处理多个信息抽取任务。在这种形式化下,多个结构化对象按照预定义的顺序连接成目标序列。然而,根据结构化对象的内在性质,多个结构化对象应构成一个无序集。因此,这种形式化引入了潜在的顺序偏见,可能会损害模型的学习。针对这个问题,本文提出了一种集合学习方法,通过考虑结构化对象的多种排列来近似优化集合概率。值得注意的是,我们的方法不需要对模型结构进行任何修改,使其容易集成到现有的生成式信息抽取框架中。实验表明,我们的方法在大量任务和数据集上改善了现有的框架。

标题:Learning to Describe for Predicting Zero-shot Drug-Drug Interactions
作者:Fangqi Zhu, Yongqi Zhang, Lei Chen, Bing Qin, Xuifeng Xu*
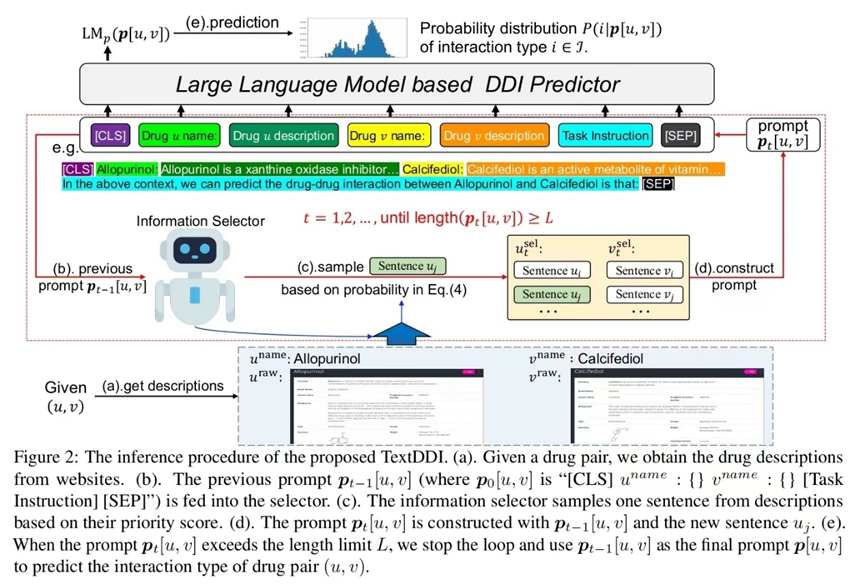
简介:药物之间的不良相互作用(DDIs)可能会损害同时使用药物的有效性,这在医疗保健领域构成了一个重大挑战。传统的DDI预测计算方法可能由于缺乏知识而无法捕捉新药物的相互作用。本文提出了一个新的问题设置,即zero-shot DDI预测,用于处理新药物的情况。借助来自DrugBank和PubChem等在线数据库的文本信息,提出了一种创新方法TextDDI,其中包括基于大型语言模型(LLM)的DDI预测器和基于强化学习(RL)的信息选择器,使其能够选择简洁且相关的文本以准确预测新药物的DDI。实验结果显示所提方法在包括zero-shot和few-shot DDI预测在内的多种设置下的优点,并且所选择的文本在语义上是相关的。
题目:Reducing Spurious Correlations in Aspect-based Sentiment Analysis with Explanation from Large Language Models
作者:Qianlong Wang, Keyang Ding, Bin Liang, Min Yang, Ruifeng Xu*
摘要:在对方面的情感特征进行建模时,现有的大部分模型容易学习输入文本中某些单词和输出标签之间的虚假相关性。这种虚假相关性可能会破坏ABSA模型的鲁棒性和泛化性。这个问题的一个直接解决方案是让模型“看到”并学习情感表达的解释,而不是某些单词。受此启发,本文利用来自大语言模型对每个方面情感的解释来缓解ABSA中的虚假相关性。首先,构造了提示模板,其中包含句子、方面和情感标签。该模板提示大语言模型生成合适的解释来说明情感的原因。然后,我们提出两种简单而有效的方法来利用解释来防止学习虚假相关性。将所提的方法与一些代表性的ABSA模型结合并在四个数据集上的实验结果表明,该方法可以实现性能提升并增强ABSA模型的鲁棒性和泛化能力。
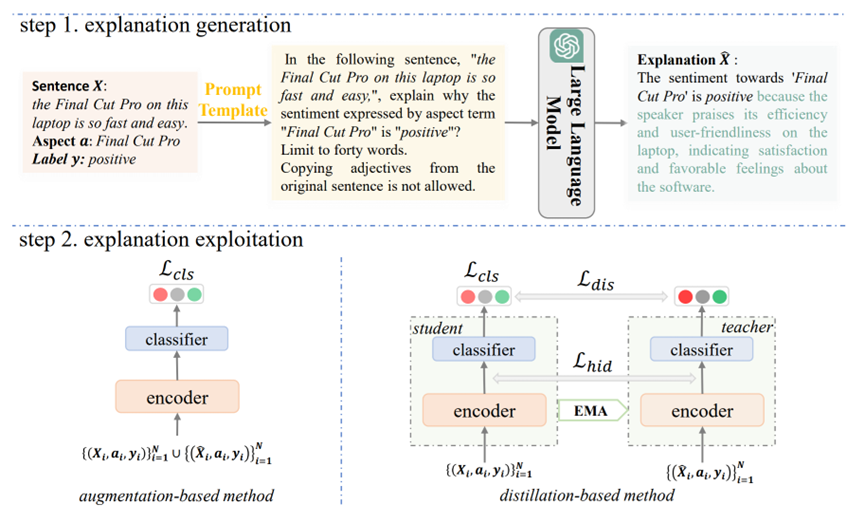
标题:An Empirical Study on Multiple Knowledge from ChatGPT for Emotion Recognition in Conversations
作者:Geng Tu, Bin Liang, Bing Qin, Kam-Fai Wong, Ruifeng Xu*
简介:多种知识(例如,共指,主题,情感原因等)已被证明在情绪检测中是有效的。然而,由于缺乏已注释的数据,以及获取此类知识所涉及的高成本,目前在对话情绪识别(ERC)中探索这些知识的研究极少。本文提出了一个多知识融合模型(MKFM),以有效地整合LLMs生成的这些知识用于ERC任务,并在实证研究中研究其对模型的影响。在三个公共数据集上的实验结果证明了多种知识对ERC任务的有效性。此外,本文还对这些知识的贡献和互补性进行了更详细的分析。
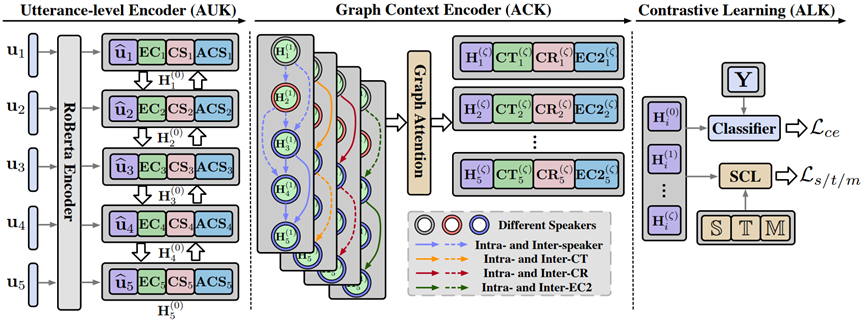
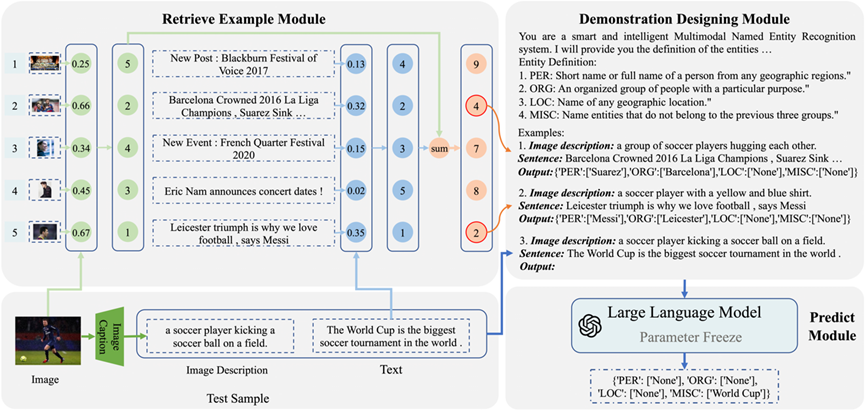
标题: In-context Learning for Few-shot Multimodal Named Entity Recognition
作者: Chenran Cai, Qianlong Wang, Bin Liang, Bing Qin, Min Yang, Kam-Fai Wong, Ruifeng Xu*
简介:现有的多模态命名识别(MNER)研究在部分实体类别拥有充足的标注资源的支持下,取得了优异的性能。然而,在现实场景中,新的实体类别不断涌现,事先枚举所有的实体类别是不现实的,而且为每个新类别重新标注数据集是耗时费力的。因此,本文将MNER任务推广到少样本多模态命名实体识别(FewMNER)任务,旨在仅利用少量的标注样本有效地定位和识别文本-图像对中的命名实体。接着,本文探索了大型语言模型的上下文学习能力,并设计了一种新颖的框架来处理FewMNER任务。该框架包含了三个关键环节:转换视觉模态、选择有用的样本和设计有效的指令。具体来说,该框架首先利用图像描述模型将图像转换为文本描述,使大型语言模型能够从视觉模态中获得信息。然后,根据文本和图像模态的相似度排名之和来选择k个最近的样本,作为上下文学习的示例。最后,该框架利用MNER任务的定义和每个实体类别的含义作为指令,来引导大型语言模型。在两个基准数据集的实验结果表明,我们的框架在多种少样本设置下均优于基线模型。
标题:Cue-CoT: Chain-of-thought Prompting for Responding to In-depth Dialogue Questions with LLMs
作者:Hongru Wang#, Rui Wang#, Fei Mi, Yang Deng, Zezhong Wang, Bin Liang, Ruifeng Xu, Kam-Fai Wong
大型语言模型(LLMs),例如ChatGPT,使得对话系统具有强大的语言理解和生成能力。然而,大部分先前的工作都是直接引导LLMs基于对话上下文生成回应,忽视了上下文中展现出的关于用户状态的潜在语言线索。基于用户潜在心理、个性等信息的深度对话场景对现有的LLMs来说是一个挑战,因为它们很难仅通过一步生成就弄清楚用户的隐藏需求并给出满意的回答。为了解决这个问题,提出了一种新颖的基于语言线索的思维链(Cue-CoT)。通过中间的推理步骤增强了LLMs的推断能力,以找到对话中用户话语中潜在的线索,进而为用户提供更个性化和吸引人的回应。为了评估我们提出的方法,针对对话过程中的三个主要语言线索:用户个性,用户情绪和用户心理,构建了一个深度对话问题的基准测试集合,其中包括6个中英文数据集(中英文各三个)。在这个基准测试进行了大量的实验结果表明,Cue-CoT方法在helpfulness和acceptness方面都优于标准的提示方法(LLMs直接进行回复),显示了很好的优越性。
|