此文章选自公众号PaperWeekly
摘要
跨目标立场检测(cross-target stance detection)的最大挑战在于我们需要从有限的已知目标(target)样本中挖掘有用的语义信息来对未知的目标进行立场检测。我们发现,由于待预测样本的目标是未知的,所以很难通过知识迁移或特征共享的方法将已知目标的训练特征迁移至未知目标的立场学习当中。并且,不同的词语在针对不同目标表达立场时的作用是不一样的。
基于这一发现,我们探索了一种新的从立场语言表达出发构建目标自适应的依赖关系图方法,该方法可以从已有语料中自动地为不同目标构建立场信息表达关系图,称为目标自适应语用依赖图(target-adaptive pragmatics dependency graph, TPDG)。
与以往基于特征共享和知识迁移的方法不同,TPDG 同时考虑了目标自身特有的立场表达信息和不同目标之间的立场表达联系。通过对目标特有立场表达信息的建模和学习,可以将这些特有信息用于协助有关联的未知目标立场特征学习;此外,通过对目标间立场表达联系的建模和学习,可以有效挖掘出源目标和未知目标的立场表达依赖关系。
最终通过一个多层的交互式图卷积块(interactive GCN blocks)对上下文表示和目标自适应图进行建模和特征学习,得到未知目标的立场检测结果。

论文标题:
Target-adaptive Graph for Cross-target Stance Detection
论文链接:
http://www.hitsz-hlt.com/paper/TPDG-WWW2021.pdf
方法
给定源目标的立场标注数据集 以及未知目标的数据 ,其中
表示源目标数据中的目标,
表示关于该目标的文本描述,
是对应的立场标签。
跨目标立场检测任务是在源目标数据集
上训练模型来预测未知目标数据集
的立场标签。针对这一任务,我们提出的 TPDG(target-adaptive pragmatics graph)模型框架如图 1 所示:
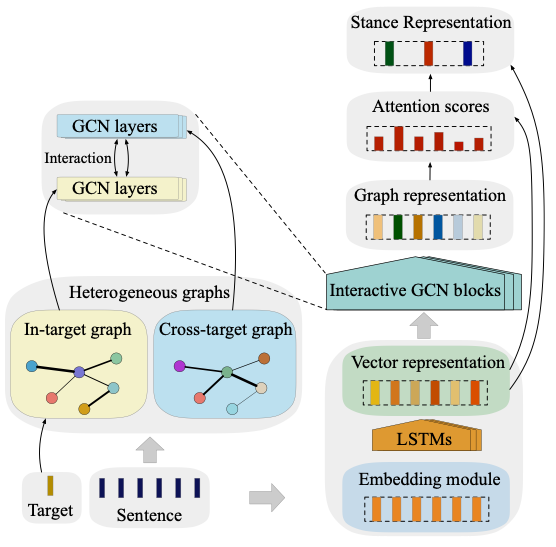
▲ 图1:目标自适应图网络模型框架
目标自适应语用依赖图的构建主要分为语用权重计算和目标自适应语用依赖图构建两个步骤。
语用权重计算:
为了更好建模立场表达的上下文,我们从目标自身出发,挖掘词语针对不同目标的语用权重,即词语相对于不同目标的立场表达角色。
对于每一个词语
要么针对特定目标表达出特有的立场信息(in-target perspective),要么针对不同目标表达出相近的立场信息(cross-target perspective)。
本文从这两个角度出发来计算词语的语用权重,即目标内(in-target)语用权重
和目标间(cross-target)语用权重
。词语
的目标内语用权重表达的是该词语和某个目标的关联程度,因此同一个词语对于不同的目标可能会充当不同的角色,即有不一样的语用权重。
另一方面,词语的目标间语用权描绘的是词语在所有目标中的通用分布特征,即目标间语用权重越大说明该词语对不同目标的影响程度是相似的,相反如果目标间语用权重越小说明该词语只伴随特定目标才表现出立场信息。
基于词语在数据集中出现的频率先验统计信息,词语
目标内语用权重
的计算方式如下公式所示:
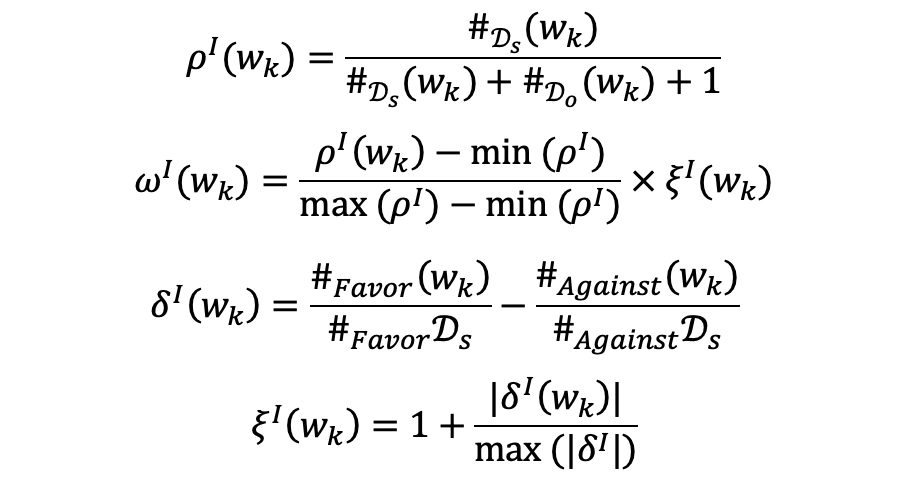
其中
和
分别为词语
在特定目标和其他目标中出现的次数。
和
分别表示词语
在已知样例的不同类别(假设有 favor 和 against 两个类别)中出现的次数。
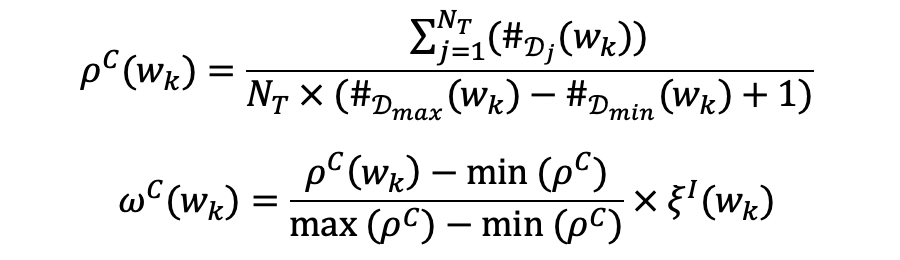
其中
为数据集中目标的个数,
和
分别为词语
出现最多的数据集次数和最少次数。
经过上面的计算后我们词表中的任意一个词语
对于特定目标都有两个语用权重
和
。接下来本文将使用这两种权重来构建目标自适应语用依赖图。
目标自适应语用依赖图构建:
对于每一个输入文本我们需要构建目标自适应语用依赖图。即根据目标特有语用权重和目标间语用权重来构造目标内关系图
(in-target graph)
和目标间关系图(cross-target graph)
:
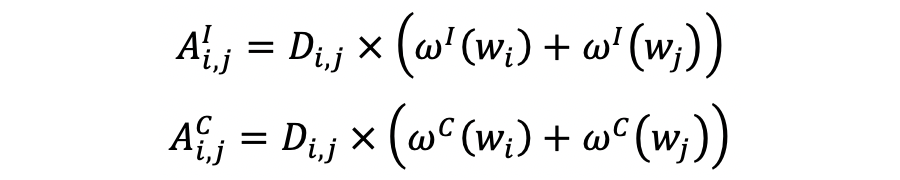
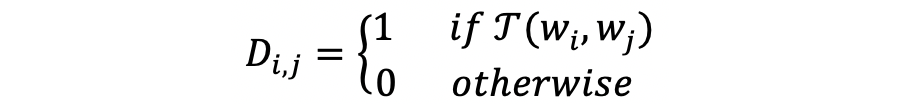
对于给定的输入文本向量矩阵
,本文通过一个双向 LSTM(Bi-LSTM)网络可以得到文本的隐藏表示:
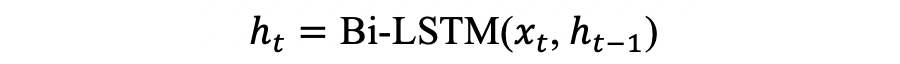
基于文本的隐藏表示和 in-target graph、cross-target graph,本文使用一个多层交互式图卷积块来交互学习文本的目标内和跨目标立场特征信息,其中,第 l 层图卷积块计算如下:
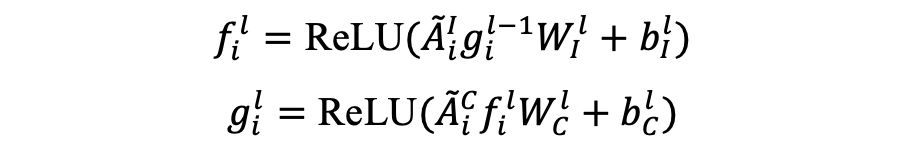
其中
为上层图卷积的隐藏输出,
为关系图的规范化表示,
为关系图的度。对于第一层图网络有:
。
实验
我们在 2 个公开的跨目标立场检测数据集(SEM16 和 WT-WT)中的 12 个跨目标立场检测任务中进行实验。实验结果显示我们提出的 TPDG 方法在各个跨目标立场检测任务中的性能都达到了最优。

▲ 表1:SEM16数据集的实验结果
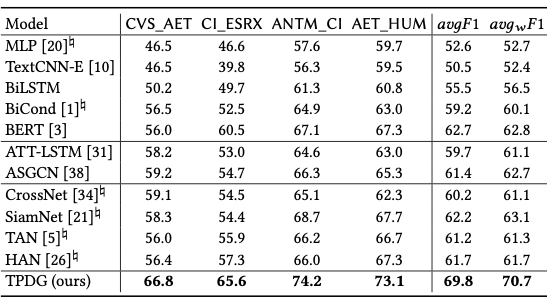
▲ 表2:WT-WT数据集的实验结果
结论
本文针对跨目标立场检测提出一种自动学习词语在立场表达中的角色来构建目标自适应图(TPDG)的方法。该方法通过学习词语的目标内和目标之间的语用权重来为上下文构建目标内关系图(in-target graph)和目标间关系图(cross-target graph)。
基于此,本文进一步提出一种多层的交互式图卷积块(interactive GCN blocks)网络来对上下文、目标内关系图、以及目标间关系图进行建模,从而为未知目标自动学习上下文的立场表达信息,得到未知目标的立场检测结果。
实验结果表明,本文提出的目标自适应图方法在不同数据集的跨目标立场检测任务中都取得了最优性能。